Extracting Data Tables from Oklahoma Booze Licensees PDF
This PDF contains detailed tables listing alcohol licensees in Oklahoma. It has multi-line cells making it hard to extract data accurately. Challenges include alternative row colors instead of lines ("zebra stripes"), complicating row differentiation and extraction.

Animal 911 Calls Extraction from Rainforest Cafe Report
This PDF is a service call report covering 911 incidents at the Rainforest Cafe in Niagara Falls, NY. We're hunting for animals! The data is formatted as a spreadsheet within the PDF, and challenges include varied column widths, borderless tables, and large swaths of missing data.
Complex Extraction of Law Enforcement Complaints
This PDF contains a set of complaint records from a local law enforcement agency. Challenges include its relational data structure, unusual formatting common in the region, and redactions that disrupt automatic parsing.

Extracting Use-of-Force Records from Vancouver Police PDF
This PDF contains detailed records of Vancouver Police's use-of-force incidents, provided after a public records request by journalists. Challenges include its very very very small font size and lots of empty whitespace.

Extracting Business Insurance Details from BOP PDF
This PDF is a complex insurance policy document generated for small businesses requiring BOP coverage. It contains an overwhelming amount of information across 111 pages. Challenges include varied forms that may differ slightly between carriers, making extraction inconsistent. It has to deal with different templated layouts, meaning even standard parts can shift when generated by different software.

Bad OCR in a board of education annual financial report
This PDF is all sorts of information about the Board of Education in Liberty County, Georgia
OCR and AI magic
Master OCR techniques with Natural PDF - from basic text recognition to advanced LLM-powered corrections. Learn to extract text from image-based PDFs, handle tables without proper boundaries, and leverage AI for accuracy improvements.
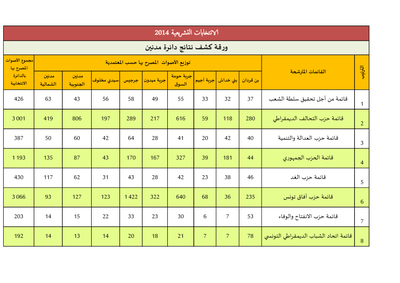
Arabic Election Results Table Extraction from Mednine PDF
This PDF has a data table showing election results from the Tunisian region of Mednine. Challenges include spanning header cells and rotated headers. It has Arabic script.
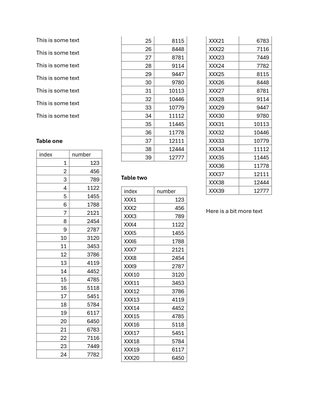
Working with page structure
Extract text from complex multi-column layouts while maintaining proper reading order. Learn techniques for handling academic papers, newsletters, and documents with intricate column structures using Natural PDF's layout detection features.

ICE Detention Facilities Compliance Report Extraction
This PDF is an ICE report on compliance among detention facilities over the last 20-30 years. Our aim is to extract facility statuses and contract signatories' names and dates. Challenges include strange redactions, blobby text, poor contrast, and ineffective OCR. It has handwritten signatures and dates that are redacted.
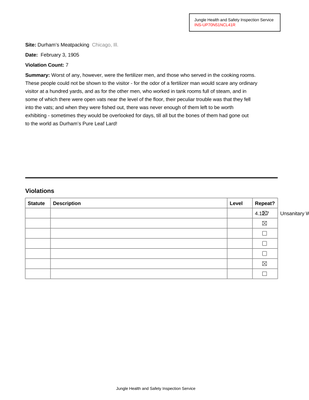
Natural PDF basics with text and tables
Learn the fundamentals of Natural PDF - opening PDFs, extracting text with layout preservation, selecting elements by criteria, spatial navigation, and managing exclusion zones. Perfect starting point for PDF data extraction.

Extracting Complex Data from Serbian Regulatory PDF
This PDF contains parts of Serbian policy documents, crucial for a research project analyzing industry policies across countries. The challenge lies in extracting a large table that spans pages (page 90 to 97) and a math formula on page 98, all in Serbian. Both elements lack clear boundaries between pages, complicating extraction.

Extracting Text from Georgia Legislative Bills
This PDF contains legal bills from the Georgia legislature, published yearly. Challenges include extracting marked-up text like underlines and strikethroughs. It has line numbers that complicate text extraction.

CIA Document Analysis
Extracting information from declassified CIA documents using AI

Extracting State Agency Call Center Wait Times from FOIA PDF
This PDF contains data on wait times at a state agency call center. The main focus is on the data on the first two pages, which matches other states' submission formats. The later pages provide granular breakdowns over several years. Challenges include it being heavily pixelated, making it hard to read numbers and text, with inconsistent and unreadable charts.

Complex Table Extraction from OECD Czech PISA Assessment
This PDF is a document from the OECD regarding the PISA assessment, provided in Czech. The main extraction goal is to get the survey question table found on page 9. Challenges include the weird table format, making it hard to extract automatically.
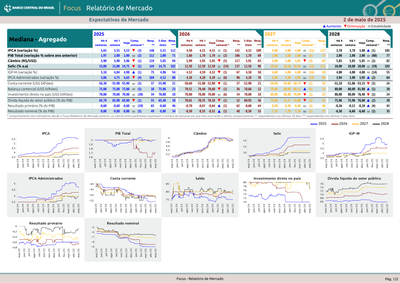
Extracting Economic Data from Brazil's Central Bank PDF
This PDF is the weekly “Focus” report from Brazil’s central bank with economic projections and statistics. Challenges include commas instead of decimal points, images showing projection changes, and tables without border lines that merge during extraction.