
Extracting State Agency Call Center Wait Times from FOIA PDF
This PDF contains data on wait times at a state agency call center. The main focus is on the data on the first two pages, which matches other states' submission formats. The later pages provide granular breakdowns over several years. Challenges include it being heavily pixelated, making it hard to read numbers and text, with inconsistent and unreadable charts.
The submission said "the first two pages" so I'm going with that. The rest of the pages are insane and will need a wholly separate writeup.
from natural_pdf import PDF
pdf = PDF("statecallcenterdata_redacted.pdf")
page = pdf.pages[0]
page.show()
The pages are images so they don't have text, but we can always double-check.
# No results? Needs OCR!
print(page.extract_text())I love surya so I'm going to use it instead of the default of easyocr. Two ways to check the results: look at where it found text and look at what the text is.
page.apply_ocr('surya')
page.find_all('text').show(crop=True)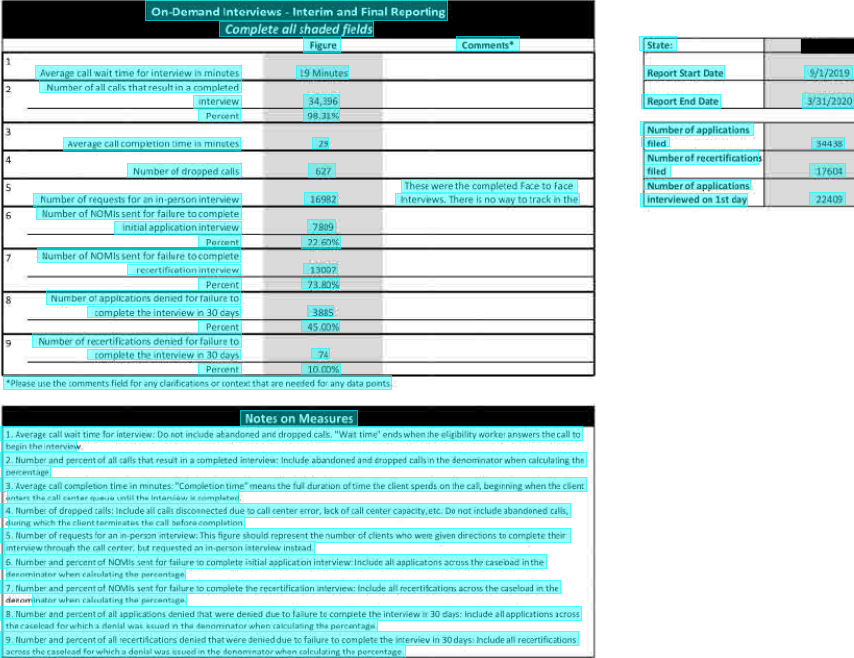
And now we'll look at what the text is.
print(page.extract_text(layout=True)) On-Demand Interviews - Interim and Final Reporting
Complete all shaded fields
Figure Comments* State:
Average call wait time for interview in minutes 19 Minutes <b>Report Start Date</b> 9/1/2019
Number of all calls that result in a completed
.interview 34,396 <b>Report End Date</b> 3/31/2020
Percent 98.31%
Number of applications
Average call completion time in minutes 29 filed 34438
Number of recertification:
Number of dropped calls 627 filed 17604
These were the completed Face to face Number of applications
Number of requests for an in-person interview 16982 Intervews. There is no way to track in the intervlewed on 1st day 22409
Number of NOMIs sent for failure to complete
initial application interview 7809
Percent 22.60%
Number of NOMIs sent for failure to complete-
recertification interview. 13007
Percent 73.80%
Number of applications denied for failure to
complete the interview in 30 days 3885
Percent 45.00%
Number of recertifications denied for failure to
complete the interview in 30 days. 74
Percent 10.00%
*Please use the comments field for any clarifications or context that are needed for any data points.
<b>Notes on Measures</b>
1. Average call wait time for interview: Do not include abandoned and dropped calls. "Wat time" ends when the eligibility worker answers the call to
begin the interview
2. Number and percent of all calls that result in a completed interview; Include abandoned and eropped calls in the denominator when calculating the
percentage.
3. Average call completion time in minutes: "Completion time" means the full duration of time the client spends on the call, beginning when the client.
nters the call center queue until the Interview is completed
4. Number of dropped rails: Include all calls disconnected due to call center error, lack of call center capacity, etc. Do not include abandoned calls,
uring which the client terminates the call before completion.
5. Number of requests for an in-person interview: This figure should represent the number of clients who were given directions to complete their
interview through the call certer, but requested an in-person interview instead.
6. Number and percent of NOMIs sent for failure to complete initial application interview: Include all applications across the casebad in the
ferominator when calculating the percentage.
7. Number and percent of NOMIs sent for failure to complete the recertification interview: Include all recertifications across the caseload in the
nator when calculating the percentage.
8. Number and percent of all applications denied that were denied due to failure to complete the interview in 30 days: include all applications across
the caselcad for which a denial was ssued in the denominator when calculating the percentage.
9. Number and percent of all recertifications denied that were denied due to failure to complete the interviev in 30 days: Include all recertifications
across the caselead for which a denial was issued in the denominator when calculating the percentage.
To get the table area, we get everything from the "Figure" header down to "Please use the comments field"
table_area = (
page
.find('text:contains(Figure)')
.below(
until='text:contains(Please use the comments)',
include_endpoint=False
)
)
table_area.show(crop='wide')
We need to cut it in on the sides a little bit, and expand it on the bottom. I just pick some manual values because I'm lazy, should probably be a better way to resize things based on selectors.
table_area = (
page
.find('text:contains(Figure)')
.below(
until='text:contains(Please use the comments)',
include_endpoint=False
)
.expand(
right=-(page.width * 0.58),
left=-30,
bottom=3
)
)
table_area.show(crop='wide')
Now we can see all the text in our area.
table_area.find_all('text').show(crop=True)
For some reason we can't just use .extract_table('stream') on this, even though there are some nice gaps between each column. Oh well!
Instead we'll throw three vertical dividers in and then shuffle then around until they don't intersect any of the text. The horizontal borders are easier because they're just lines.
from natural_pdf.analyzers.guides import Guides
guide = Guides(table_area)
guide.vertical.divide(3)
guide.vertical.snap_to_whitespace(detection_method='text')
guide.horizontal.from_lines()
guide.show()
And now we can grab the table!
df = (
guide
.extract_table()
.to_df(
header=['value', 'amount', 'comments']
)
)
df| value | amount | comments | |
|---|---|---|---|
| 0 | Number of all calls that result in a completed... | 34,396 | None |
| 1 | Percent | 98.31% | None |
| 2 | Average call completion time in minutes | 29 | None |
| 3 | Number of dropped calls | 627 | None |
| 4 | Number of requests for an in-person interview\... | 16982 Intervews. There is no way to track in the | These were the completed Face to face\nInterve... |
| 5 | Number of NOMIs sent for failure to complete\n... | 7809 | None |
| 6 | Percent | 22.60% | None |
| 7 | Number of NOMIs sent for failure to complete-\... | 13007 | None |
| 8 | Percent\nNumber of applications denied for fai... | 73.80% | None |
| 9 | Number of applications denied for failure to\n... | 3885 | None |
| 10 | Percent | 45.00% | None |
| 11 | Number of recertifications denied for failure ... | 74 | None |
| 12 | Percent | 10.00% | None |
The next page is....... too hard for now.
pdf.pages[1].show()