
CIA Document Classification
Let's work with a declassified CIA document and use AI to classify and extract information.
from natural_pdf import PDF
pdf = PDF("cia-doc.pdf")
pdf.pages.show(cols=6)Output
Could get FontBBox from font descriptor because None cannot be parsed as 4 floats

Just like we did above, we can ask what category we think the PDF belongs to.
pdf.classify(
['slaughterhouse report', 'dolphin training manual', 'basketball', 'birding'],
using='text'
)
(pdf.category, pdf.category_confidence)('birding', 0.5170503258705139) I promise birding is real! The PDF is about using pigeons to take surveillance photos.
But beyond the text content, notice how all of the pages look very very different. We can also categorize each page using vision!
pdf.classify_pages(
['diagram', 'text', 'invoice', 'blank'],
using='vision'
)
for page in pdf.pages:
print(f"Page {page.number} is {page.category} - {page.category_confidence:0.3}")Output
Page 1 is text - 0.633 Page 2 is text - 0.957 Page 3 is text - 0.921 Page 4 is diagram - 0.895 Page 5 is diagram - 0.891 Page 6 is invoice - 0.919 Page 7 is text - 0.834 Page 8 is invoice - 0.594 Page 9 is invoice - 0.971 Page 10 is invoice - 0.987 Page 11 is invoice - 0.994 Page 12 is invoice - 0.992 Page 13 is text - 0.822 Page 14 is text - 0.936 Page 15 is diagram - 0.913 Page 16 is text - 0.617 Page 17 is invoice - 0.868
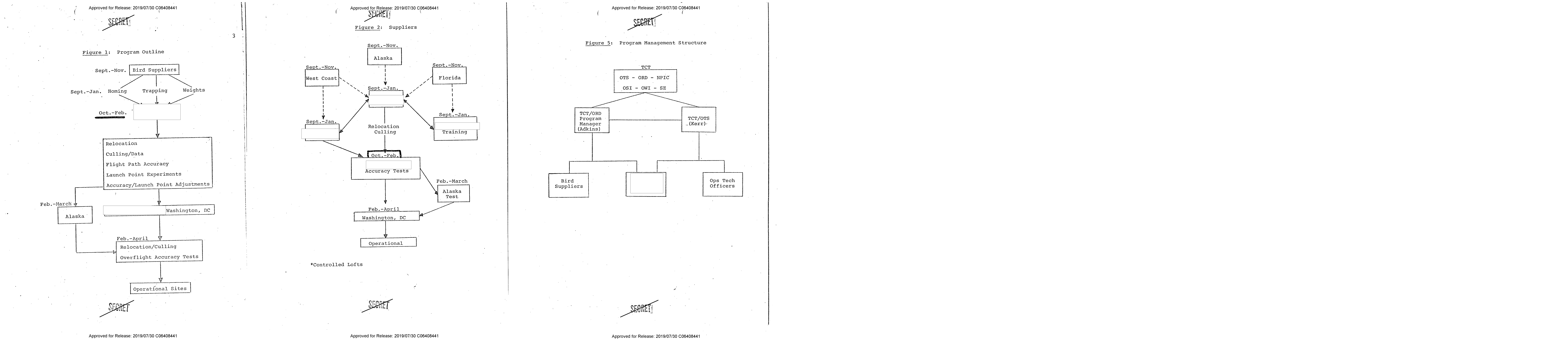
And if we just want to see the pages that are diagrams, we can .filter for them.
(
pdf.pages
.filter(lambda page: page.category == 'diagram')
.show(show_category=True)
)
We can also put them into groups.
groups = pdf.pages.groupby(lambda page: page.category)
groups.info()Output
PageGroupBy with 3 groups: ---------------------------------------- [0] 'text': 7 pages [1] 'diagram': 3 pages [2] 'invoice': 7 pages
diagrams = groups.get('diagram')
diagrams.show()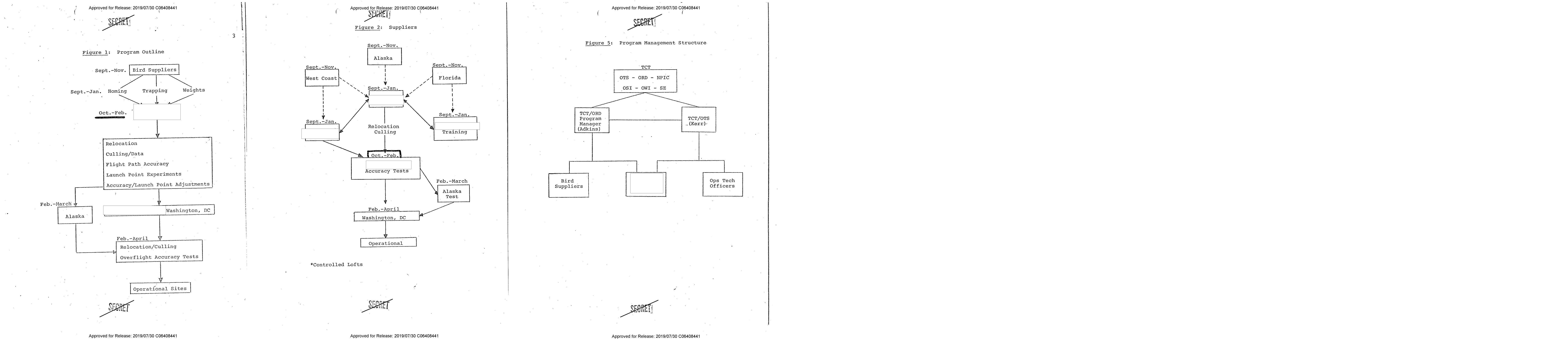
And if that's all we're interested in? We can save a new PDF of just those pages!
(
pdf.pages
.filter(lambda page: page.category == 'diagram')
.save_pdf("diagrams.pdf", original=True)
)