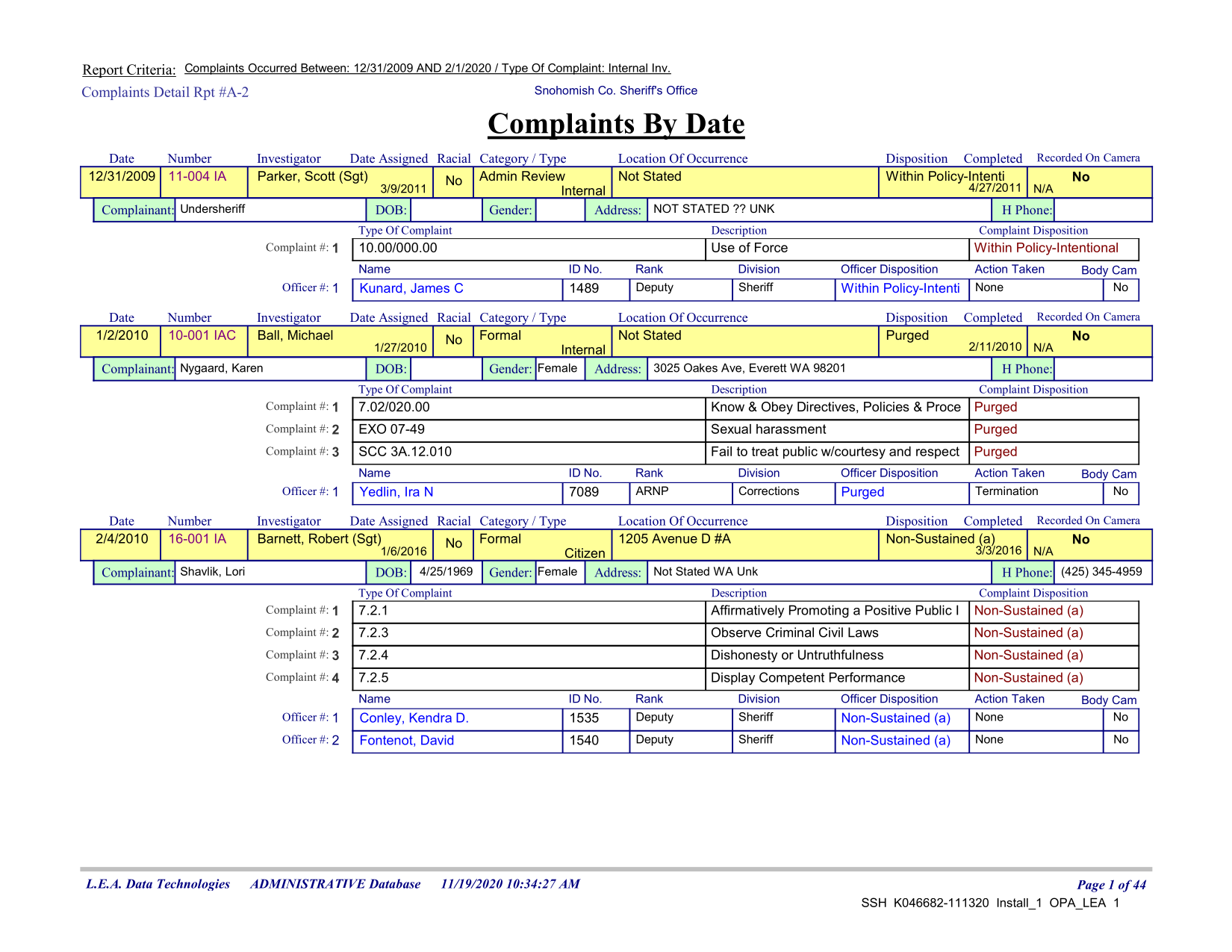
Complex Extraction of Law Enforcement Complaints
This PDF contains a set of complaint records from a local law enforcement agency. Challenges include its relational data structure, unusual formatting common in the region, and redactions that disrupt automatic parsing.
from natural_pdf import PDF
pdf = PDF("k046682-111320-opa-lea-database-install_1.pdf")
pdf.show(cols=3)
Let's look at a single page
page = pdf.pages[0]
page.show()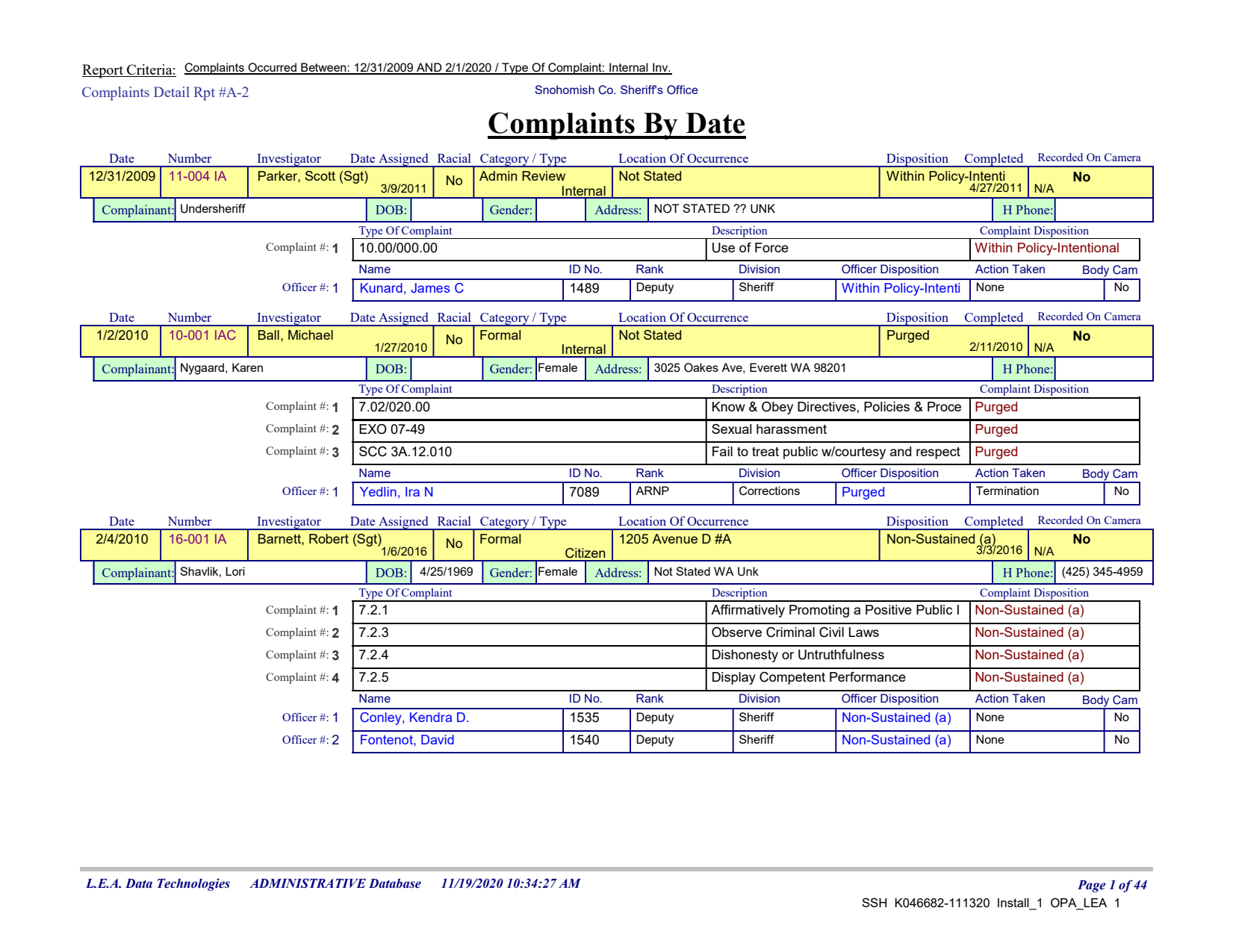
Adding exclusions
We don't like the top and bottom areas, so we'll exclude them.
pdf.add_exclusion(lambda page: page.find(text='L.E.A. Data Technologies').below(include_source=True))
pdf.add_exclusion(lambda page: page.find(text='Complaints By Date').above(include_source=True))
page.show(exclusions='black')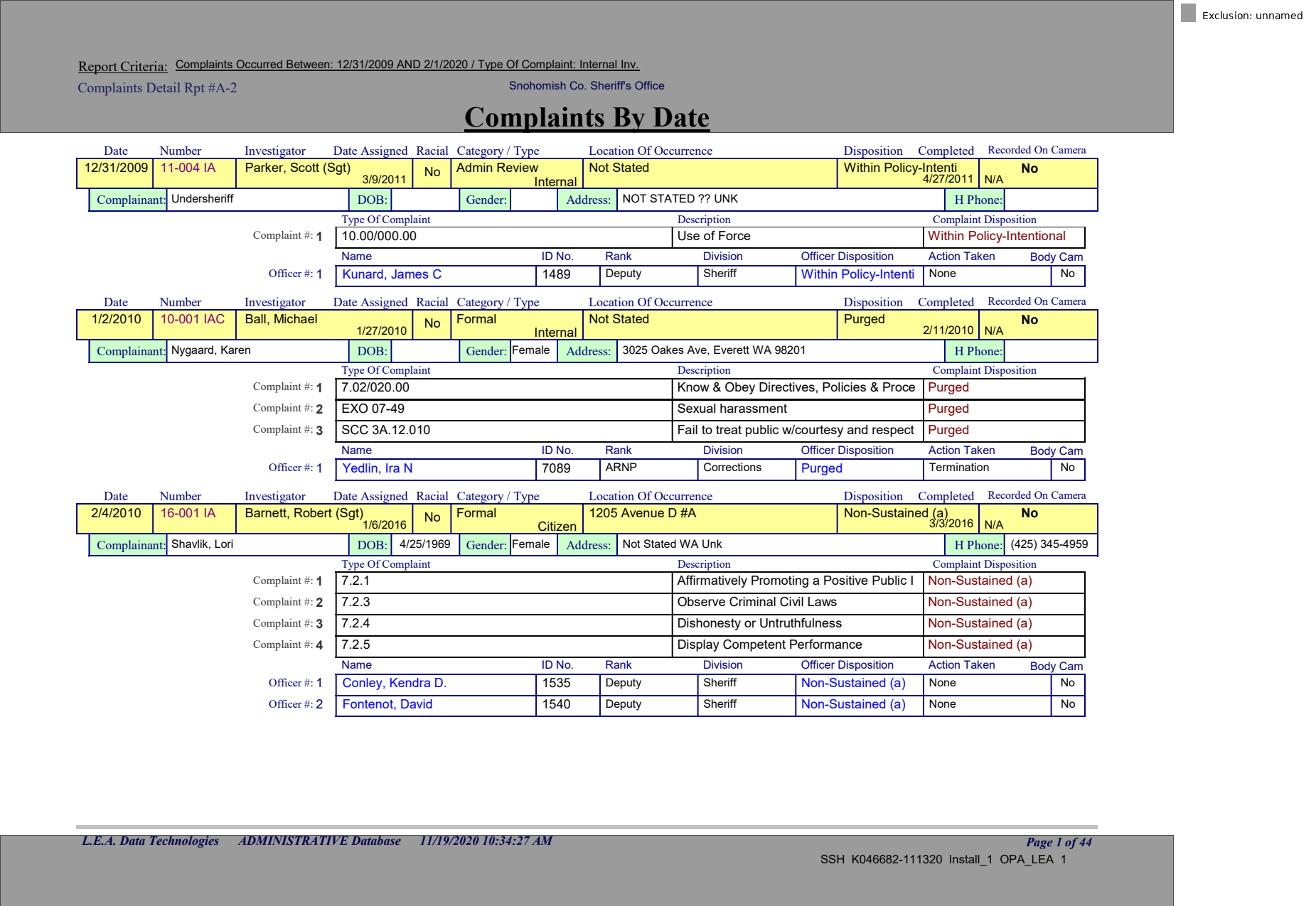
Breaking into sections
Even though you might think the colors are the best route to tackle this – they stand out! – I think text is usually the best option.
We'll tell it to break the pages into sections by the Recorded On Camera text. We tell it include_boundaries='start'.
Originally I did this with Location of Occurrence but apparently it's a little bit lower than the recording header and caused some problems later on.
sections = pdf.get_sections(
'text:contains(Recorded)',
include_boundaries='start'
)
sections.show(cols=3)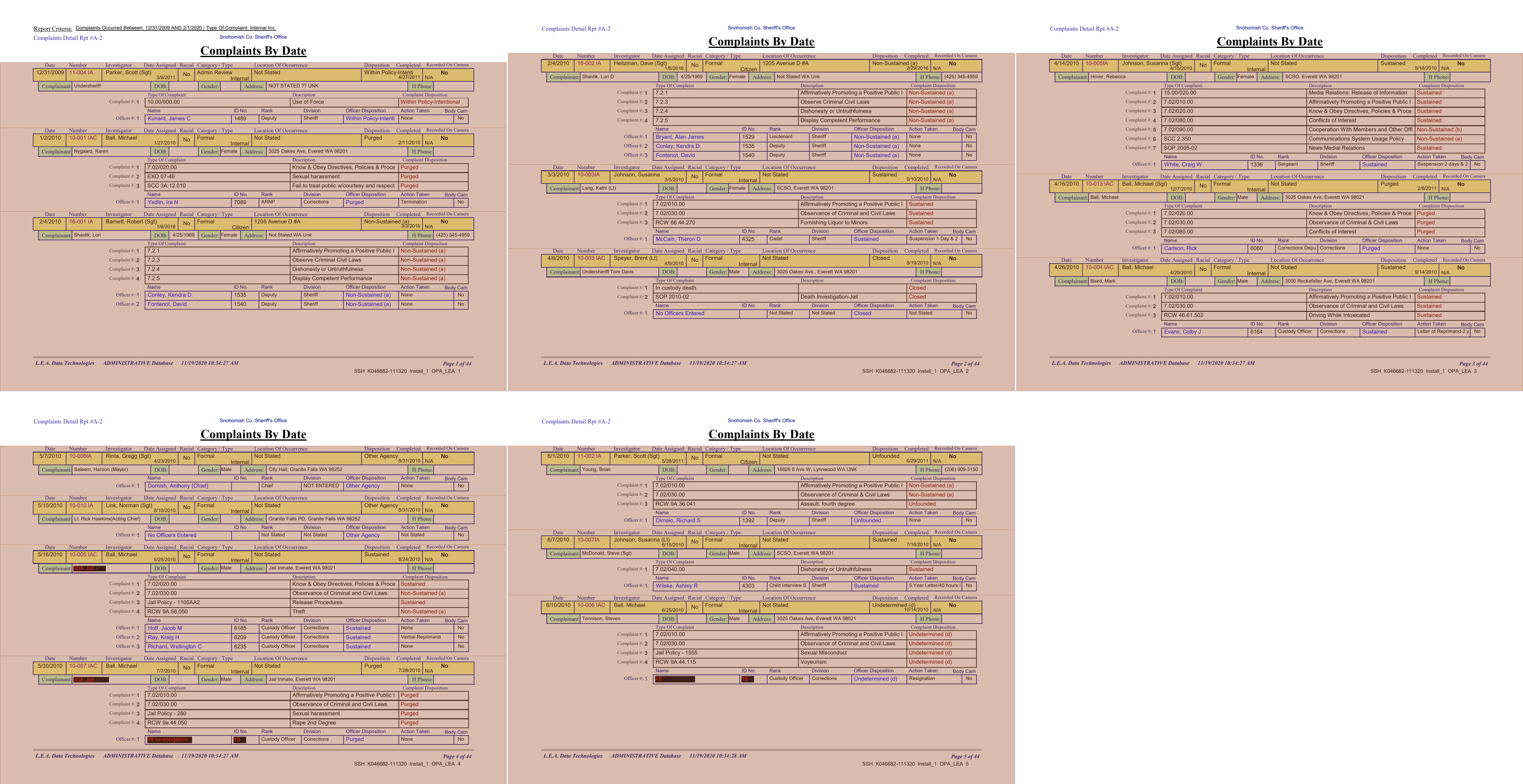
Let's look at one of the sections.
section = sections[3]
section.show(crop=True)
This extraction is made easier since they're all generally the same, they all have the same formatting even if they're missing data.
Extracting the top area
Up top we'll focus on grabbing the labels, then going right until we find a piece of text.
complainant = (
section
.find("text:contains(Complainant)")
.right(until='text')
)
print("Complainant is", complainant.extract_text())
complainant.show(crop=100)Complainant is Shavlik, Lori D
Note that date of birth and some other fields are missing. Usually this means we'd have to use right(100) or pick some manual pixel value, but it turns out even the missing data includes text elements - they're just empty! That means we can use until='text' instead of magic numbers.
dob = (
section
.find("text:contains(DOB)")
.right(until='text')
)
print("DOB is", dob.extract_text())
dob.show(crop=100)DOB is 4/25/1969
For the above/below pieces it's slightly more problematic. By default when you expand downwards, it doesn't select the entire piece of text, it only grabs the ones that intersect with your search area.
number = (
section
.find("text:contains(Number)")
.below(until='text', width='element')
)
print("Number is", number.extract_text())
number.show(crop=100)Number is 16-002
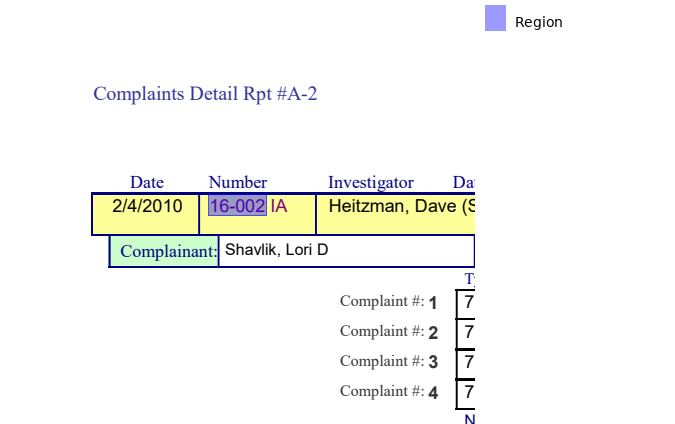
In order to be sure you get the entire thing you need to ask for text that even partially overlaps the area you have selected. This makes the area expand to cover all of the number.
number = (
section
.find("text:contains(Number)")
.below(until='text', width='element')
.find('text', overlap='partial')
)
print("Number is", number.extract_text())
number.show(crop=100)Number is 16-002 IA
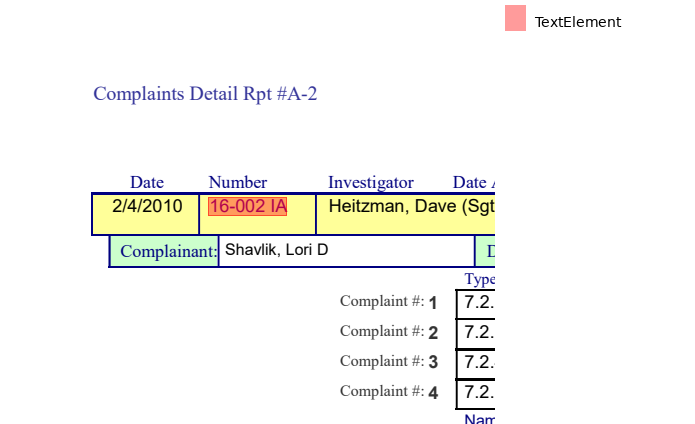
The elements like "Date Assigned" and "Completed" are a little more difficult, as you want to be sure you're only grabbing the text fully and directly underneath the label.
(
section
.find('text:contains(Date Assigned)')
.below(width='element')
.show(crop=100)
)
We do this by grabbing the area below, then asking it to find the first piece of text inside the created box full overlap. By default it only picks text that is fully inside.
(
section
.find('text:contains(Date Assigned)')
.below(width='element')
.find('text')
.extract_text()
)'1/6/2016'
If we did until='text' it would grab the first text it touched, so it would grab the Seargant.
With that all in line, when we start to grab them all it looks something like this:
complainant = (
section
.find("text:contains(Complainant)")
.right(until='text')
)
dob = (
section
.find("text:contains(DOB)")
.right(until='text')
)
address = (
section
.find("text:contains(Address)")
.right(until='text')
)
gender = (
section
.find("text:contains(Gender)")
.right(until='text')
)
phone = (
section
.find("text:contains(H Phone)")
.right(until='text')
)
date_assigned = (
section
.find('text:contains(Date Assigned)')
.below(width='element')
.find('text')
)
completed = (
section
.find('text:contains(Completed)')
.below(width='element')
.find('text')
)
recorded = (
section
.find('text:contains(Recorded)')
.below(until='text', width='element')
)
(complainant + dob + address + gender + phone + date_assigned + completed + recorded).show(crop=section)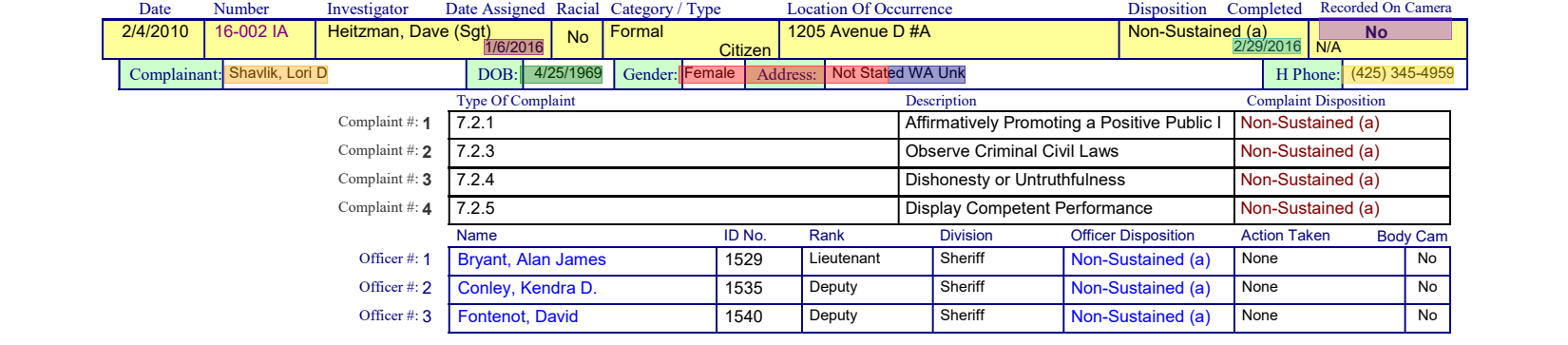
I'm sorry, I got lazy – I trust you understand and can fill the rest of them out on your own!
Capturing the complaint table
The tables might seem intimidating, but it's really only a question of isolating the area and then using .extract_table().
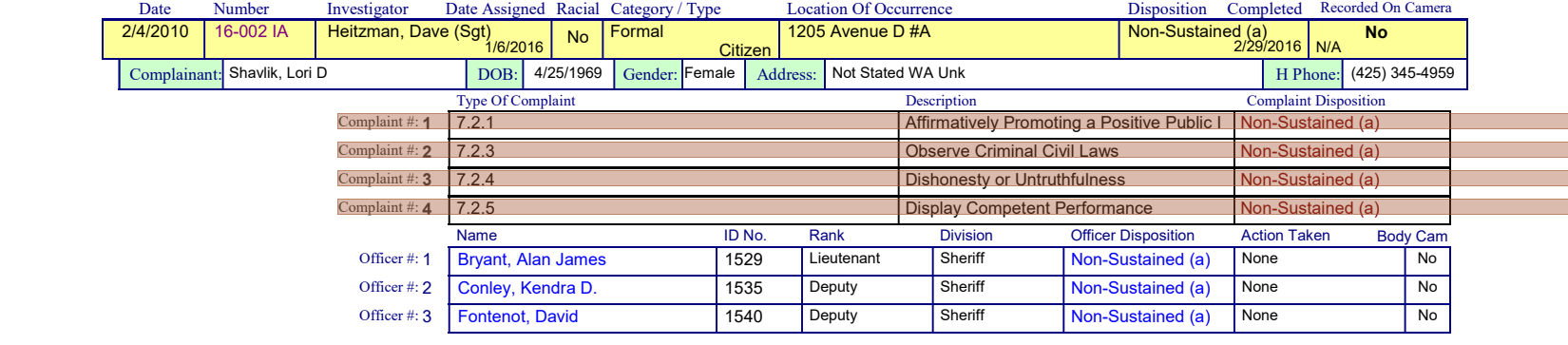
How can we describe the "Complaint" area? Well, it's **to the right of a bunch of Complaint # text.
(
section
.find_all('text:contains(Complaint #)')
.right(include_source=True)
.show(crop=section)
)
We could probably grab each of the text elements individually and parse out the columns, but instead we'll use .merge() to combine them into one big region, then nudge it up and down a little bit to capture the entire table.
(
section
.find_all('text:contains(Complaint #)')
.right(include_source=True)
.merge()
.expand(top=5, bottom=7)
.show(crop=section)
)
It's too much work to try to capture the headers programmatically, so we'll just manually type them in.
(
section
.find_all('text:contains(Complaint #)')
.right(include_source=True)
.merge()
.expand(top=5, bottom=7)
.extract_table()
.to_df(header=['Type of Complaint', 'Description', 'Complaint Disposition'])
)| Type of Complaint | Description | Complaint Disposition | |
|---|---|---|---|
| 0 | 7.2.1 | Affirmatively Promoting a Positive Public I | Non-Sustained (a) |
| 1 | 7.2.3 | Observe Criminal Civil Laws | Non-Sustained (a) |
| 2 | 7.2.4 | Dishonesty or Untruthfulness | Non-Sustained (a) |
| 3 | 7.2.5 | Display Competent Performance | Non-Sustained (a) |
Unfortunately this doesn't work on all of the tables: some of the ones with redactions trick the columnd detector! So we'll use Guides to detect a specific number of columns based on the lines.
from natural_pdf.analyzers.guides import Guides
# Find the area
table = (
section
.find_all('text:contains(Complaint #)')
.right(include_source=True)
.merge()
.expand(top=5, bottom=7)
)
# Build vertical guidelines from lines
guides = Guides(table)
guides.vertical.from_lines(n=4)
# Use the guides
(
table
.extract_table(verticals=guides.vertical)
.to_df(header=['Type of Complaint', 'Description', 'Complaint Disposition'])
)| Type of Complaint | Description | Complaint Disposition | |
|---|---|---|---|
| 0 | 7.2.1 | Affirmatively Promoting a Positive Public I | Non-Sustained (a) |
| 1 | 7.2.3 | Observe Criminal Civil Laws | Non-Sustained (a) |
| 2 | 7.2.4 | Dishonesty or Untruthfulness | Non-Sustained (a) |
| 3 | 7.2.5 | Display Competent Performance | Non-Sustained (a) |
Capturing the officers table
We take the same tack for the officers table.
table_area = (
section
.find_all('text:contains(Officer #)')
.right(include_source=True)
.merge()
.expand(top=5, bottom=7)
)
guides = Guides(table)
guides.vertical.from_lines(n=8)
(
table
.extract_table(verticals=guides.vertical)
.to_df(header=['Name', 'ID No.', 'Rank', 'Division', 'Officer Disposition', 'Action Taken', 'Body Cam'])
)| Name | ID No. | Rank | Division | Officer Disposition | Action Taken | Body Cam | |
|---|---|---|---|---|---|---|---|
| 0 | 7.2.1 | Affirmatively Promoting a Positive Public I | <NA> | Non-Sustained | <NA> | (a | ) |
| 1 | 7.2.3 | Observe Criminal Civil Laws | <NA> | Non-Sustained | <NA> | (a | ) |
| 2 | 7.2.4 | Dishonesty or Untruthfulness | <NA> | Non-Sustained | <NA> | (a | ) |
| 3 | 7.2.5 | Display Competent Performance | <NA> | Non-Sustained | <NA> | (a | ) |
A nice #todo for me is to integrate this into .extract_table. Something like .extract_table(columns=4) would look nice, no?
Combining all of the data in one CSV
First we can pop through each section and extract the information we're looking for. I added a little expansion for the Date Assigned/Completed pieces as the dates are sometimes a little longer than the header.
rows = []
for section in sections:
complainant = section.find("text:contains(Complainant)").right(until='text')
dob = section.find("text:contains(DOB)").right(until='text')
address = section.find("text:contains(Address)").right(until='text')
gender = section.find("text:contains(Gender)").right(until='text')
phone = section.find("text:contains(H Phone)").right(until='text')
investigator = (
section
.find("text:contains(Investigator)")
.below(until='text', width='element')
.find('text', overlap='partial')
)
number = (
section
.find("text:contains(Number)")
.below(until='text', width='element')
.find('text', overlap='partial')
)
date_assigned = (
section
.find('text:contains(Date Assigned)')
.below(width='element')
.expand(left=5, right=5)
.find('text')
)
completed = (
section
.find('text:contains(Completed)')
.below(width='element')
.expand(left=5, right=5)
.find('text')
)
recorded = (
section
.find('text:contains(Recorded)')
.below(until='text', width='element')
.expand(left=5, right=5)
)
row = {}
row['complainant'] = complainant.extract_text()
row['investigator'] = investigator.extract_text()
row['number'] = number.extract_text()
row['dob'] = dob.extract_text()
row['address'] = address.extract_text()
row['gender'] = gender.extract_text()
row['phone'] = phone.extract_text()
row['date_assigned'] = date_assigned.extract_text()
row['completed'] = completed.extract_text()
row['recorded'] = recorded.extract_text()
rows.append(row)
print("We found", len(rows), "rows")We found 16 rows
Now we can push it into pandas without a problem!
import pandas as pd
df = pd.DataFrame(rows)
df| complainant | investigator | number | dob | address | gender | phone | date_assigned | completed | recorded | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Undersheriff | Parker, Scott (Sgt) | 11-004 IA | Gender: | NOT STATED ?? UNK | Address: | 3/9/2011 | 4/27/2011 | No\nN/A | |
| 1 | Nygaard, Karen | Ball, Michael | 10-001 IAC | Gender: | 3025 Oakes Ave, Everett WA 98201 | Female | 1/27/2010 | 2/11/2010 | No\nN/A | |
| 2 | Shavlik, Lori | Barnett, Robert (Sgt) | 16-001 IA | 4/25/1969 | Not Stated WA Unk | Female | (425) 345-4959 | 1/6/2016 | 3/3/2016 | No\nN/A |
| 3 | Shavlik, Lori D | Heitzman, Dave (Sgt) | 16-002 IA | 4/25/1969 | Not Stated WA Unk | Female | (425) 345-4959 | 1/6/2016 | 2/29/2016 | No\nN/A |
| 4 | Lang, Kathi (Lt) | Johnson, Susanna | 10-003IA | Gender: | SCSO, Everett WA 98201 | Female | 3/5/2010 | 5/10/2010 | No\nN/A | |
| 5 | Undersheriff Tom Davis | Speyer, Brent (Lt) | 10-003 IAC | Gender: | 3025 Oakes Ave., Everett WA 98201 | Male | 4/9/2010 | 8/19/2010 | No\nN/A | |
| 6 | Hover, Rebecca | Johnson, Susanna (Sgt) | 10-005IA | Gender: | SCSO, Everett WA 98201 | Female | 4/15/2010 | 5/18/2010 | No\nN/A | |
| 7 | Ball, Michael | Ball, Michael (Sgt) | 10-013 IAC | Gender: | 3025 Oakes Ave, Everett WA 98021 | Male | 12/7/2010 | 2/8/2011 | No\nN/A | |
| 8 | Baird, Mark | Ball, Michael | 10-004 IAC | Gender: | 3000 Rockefeller Ave, Everett WA 98201 | Male | 4/29/2010 | 9/14/2010 | No\nN/A | |
| 9 | Saleem, Haroon (Mayor) | Rinta, Gregg (Sgt) | 10-006IA | Gender: | City Hall, Granite Falls WA 98252 | Male | 4/23/2010 | 8/31/2010 | No\nN/A | |
| 10 | Lt. Rick Hawkins(Acting Chief) | Link, Norman (Sgt) | 10-010 IA | Gender: | Granite Falls PD, Granite Falls WA 98252 | Address: | 8/10/2010 | 8/31/2010 | No\nN/A | |
| 11 | 05A Jail - | Ball, Michael | 10-005 IAC | Gender: | Jail Inmate, Everett WA 98021 | Male | 5/25/2010 | 6/24/2010 | No\nN/A | |
| 12 | 05A Jail - | Ball, Michael | 10-007 IAC | Gender: | Jail Inmate, Everett WA 98201 | Male | 7/7/2010 | 7/28/2010 | No\nN/A | |
| 13 | Young, Brian | Parker, Scott (Sgt) | 11-002 IA | Gender: | 16626 6 Ave W, Lynnwood WA UNK | Address: | (206) 909-3150 | 5/26/2011 | 6/29/2011 | No\nN/A |
| 14 | McDonald, Steve (Sgt) | Johnson, Susanna (Lt) | 10-007IA | Gender: | SCSO, Everett WA 98201 | Male | 6/15/2010 | 7/16/2010 | No\nN/A | |
| 15 | Tennison, Steven | Ball, Michael | 10-006 IAC | Gender: | 3025 Oakes Ave, Everett WA 98021 | Male | 6/25/2010 | 10/14/2010 | No\nN/A |
Saving the tables as combined CSVs
Usually when you have a number of similar tables in one PDF, you don't want to make a bunch of different CSV files, you want to put them all into one CSV.
We'll do that by looping through each section like we did before, but we'll also add a new column to our data: the number
import pandas as pd
officer_dfs = []
for section in sections:
# Not every section has officers, exit
# early if Officer number not mentioned
if 'Officer #' not in section.extract_text():
continue
# Grab the case number
case_number = (
section
.find("text:contains(Number)")
.below(until='text', width='element')
.find('text', overlap='partial')
.extract_text()
)
# Grab the table area
table = (
section
.find_all('text:contains(Officer #)')
.right(include_source=True)
.merge()
.expand(top=3, bottom=6)
)
# Use the guides to extract the table
guides = Guides(table)
guides.vertical.from_lines(n=8)
columns = ['Name', 'ID No.', 'Rank', 'Division', 'Officer Disposition', 'Action Taken', 'Body Cam']
officer_df = (
table
.extract_table(verticals=guides.vertical)
.to_df(header=columns)
)
# Add to your list
officer_df['case_number'] = case_number
officer_dfs.append(officer_df)
# Combine the dataframes
print("Combining", len(officer_dfs), "officer dataframes")
df = pd.concat(officer_dfs, ignore_index=True)
df.head()Combining 16 officer dataframes
| Name | ID No. | Rank | Division | Officer Disposition | Action Taken | Body Cam | case_number | |
|---|---|---|---|---|---|---|---|---|
| 0 | Kunard, James C | 1489 | Deputy | Sheriff | Within Policy-Intenti | None | No | 11-004 IA |
| 1 | Yedlin, Ira N | 7089 | ARNP | Corrections | Purged | Termination | No | 10-001 IAC |
| 2 | Conley, Kendra D. | 1535 | Deputy | Sheriff | Non-Sustained (a) | None | No | 16-001 IA |
| 3 | Fontenot, David | 1540 | Deputy | Sheriff | Non-Sustained (a) | None | No | 16-001 IA |
| 4 | Bryant, Alan James | 1529 | Lieutenant | Sheriff | Non-Sustained (a) | None | No | 16-002 IA |
Repeat the same thing for complaints (just changing n=8 to n=4) and you'll be good to go!