Multi-page flows
Sometimes you have data that flows over multiple columns, or pages, or just... isn't arranged in a "normal" top-to-bottom way.
from natural_pdf import PDF
pdf = PDF("multicolumn.pdf")
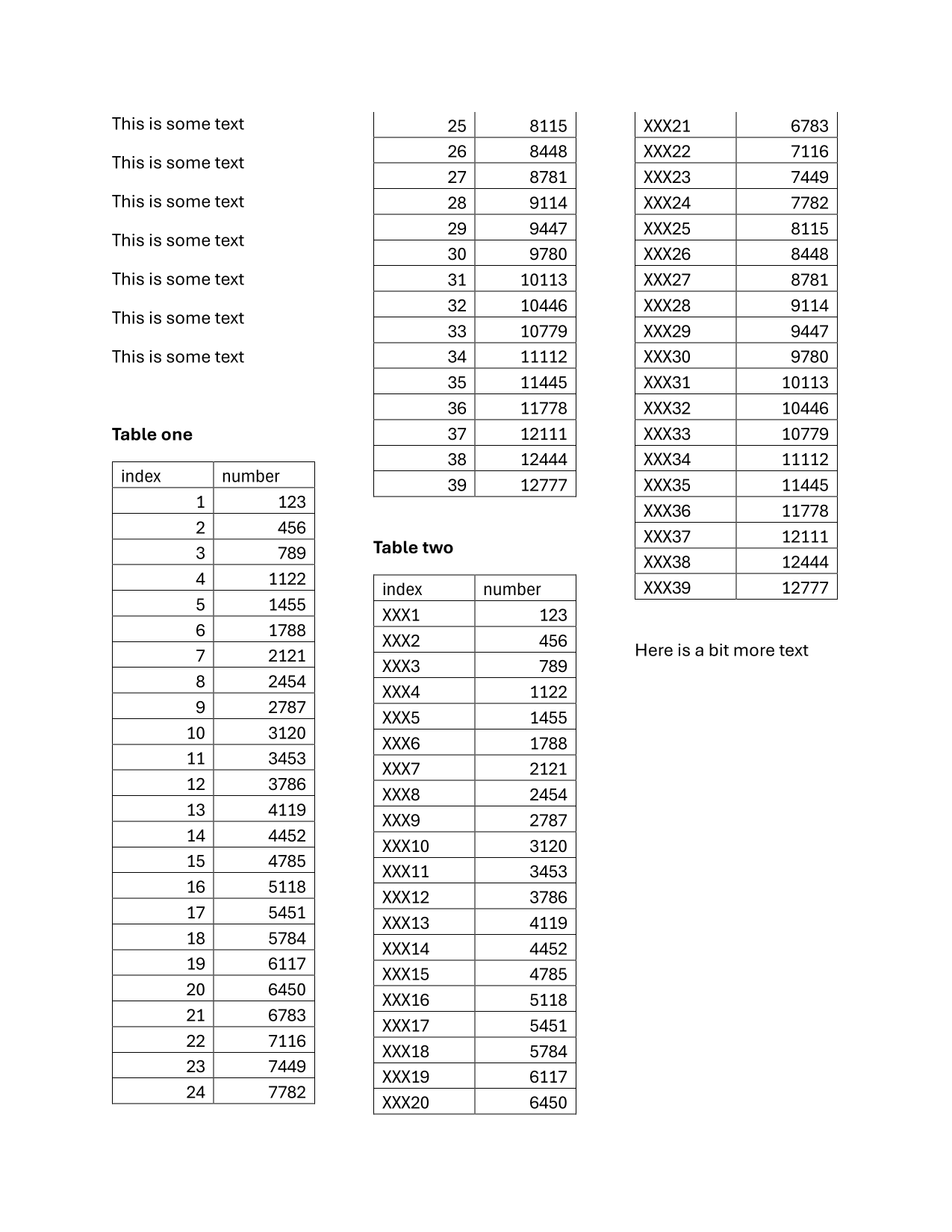
page = pdf.pages[0]
page.show()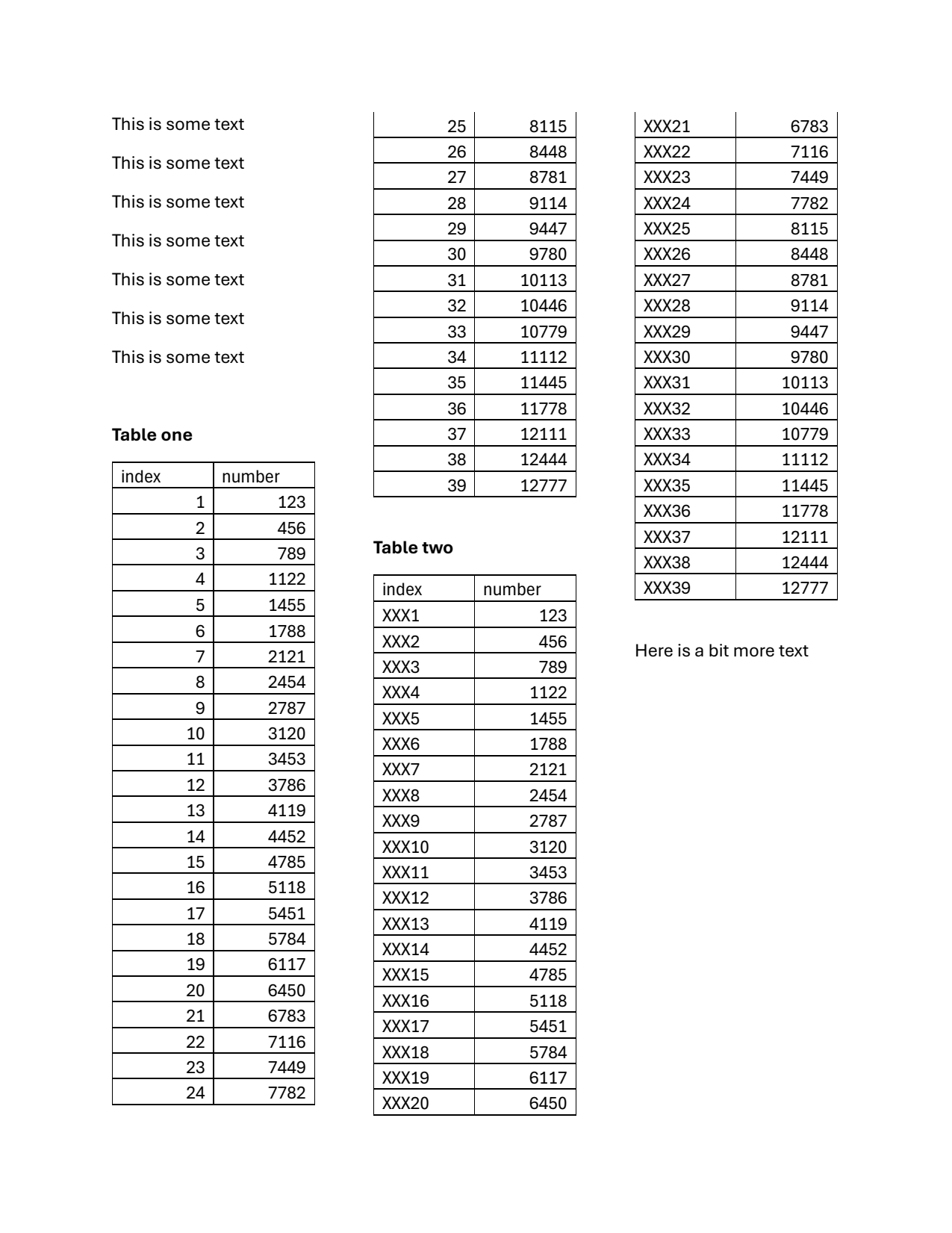
Natural PDF deals with these through reflowing pages, where you grab specific regions of a page and then paste them back together either vertically or horizontally.
In this example we're splitting the page into three columns.
left = page.region(left=0, right=page.width/3, top=0, bottom=page.height)
mid = page.region(left=page.width/3, right=page.width/3*2, top=0, bottom=page.height)
right = page.region(left=page.width/3*2, right=page.width, top=0, bottom=page.height)
page.highlight(left, mid, right)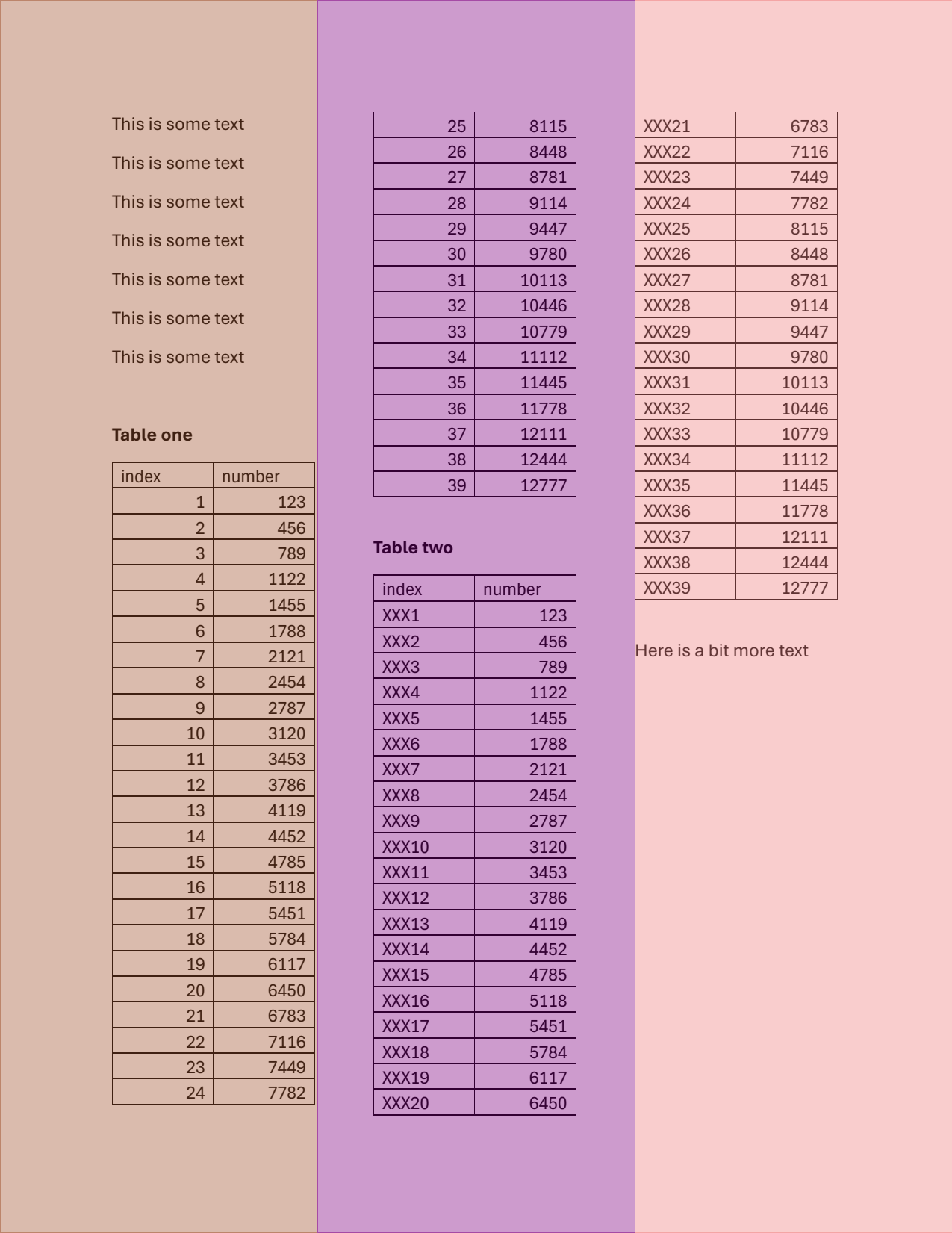
Now let's stack them on top of each other.
from natural_pdf.flows import Flow
stacked = [left, mid, right]
flow = Flow(segments=stacked, arrangement="vertical")
flow.show()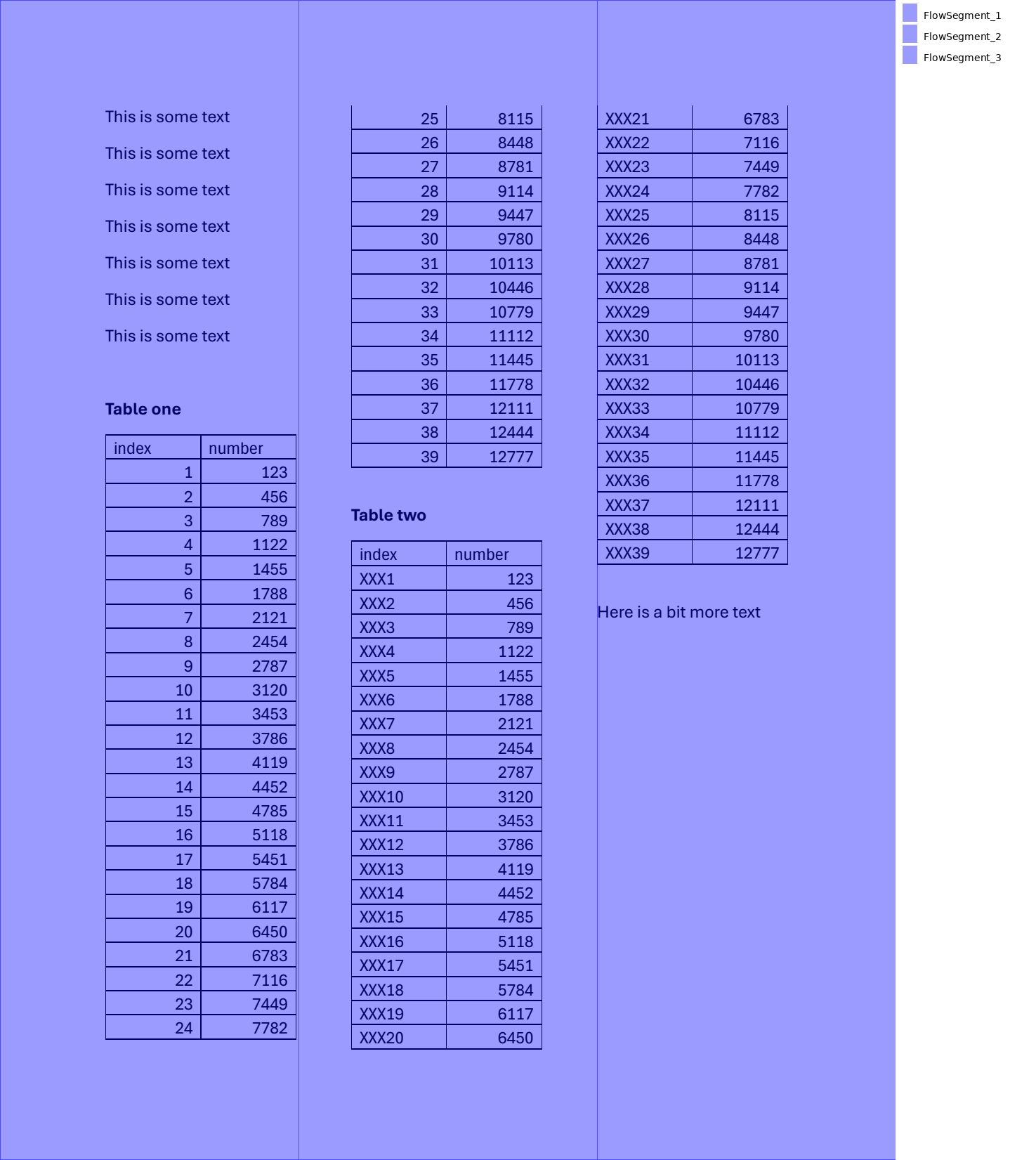
Now any time we want to use spatial comparisons, like "find something below this," it just works.
region = (
flow
.find('text:contains("Table one")')
.below(
until='text:contains("Table two")',
include_endpoint=False
)
)
region.show()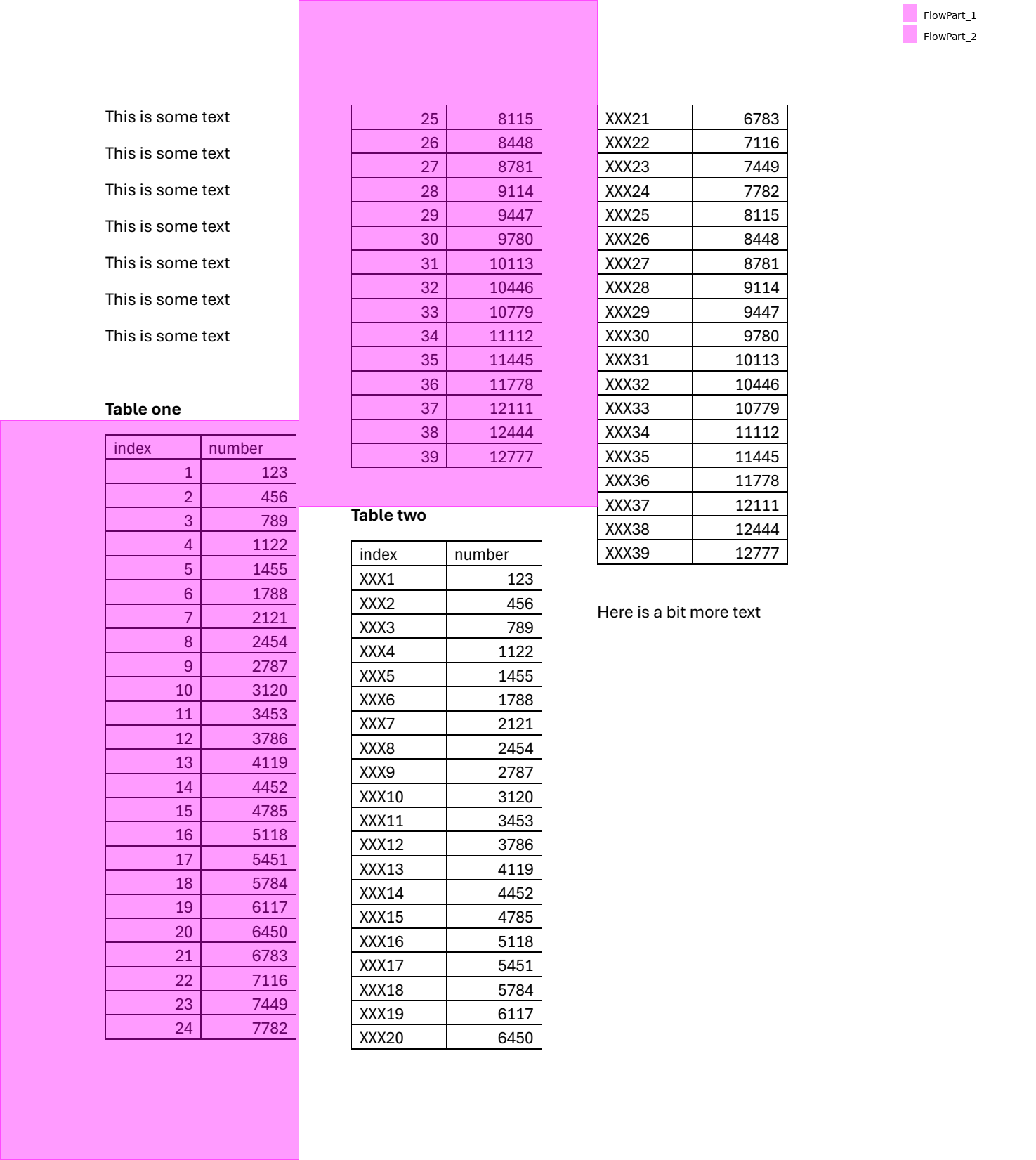
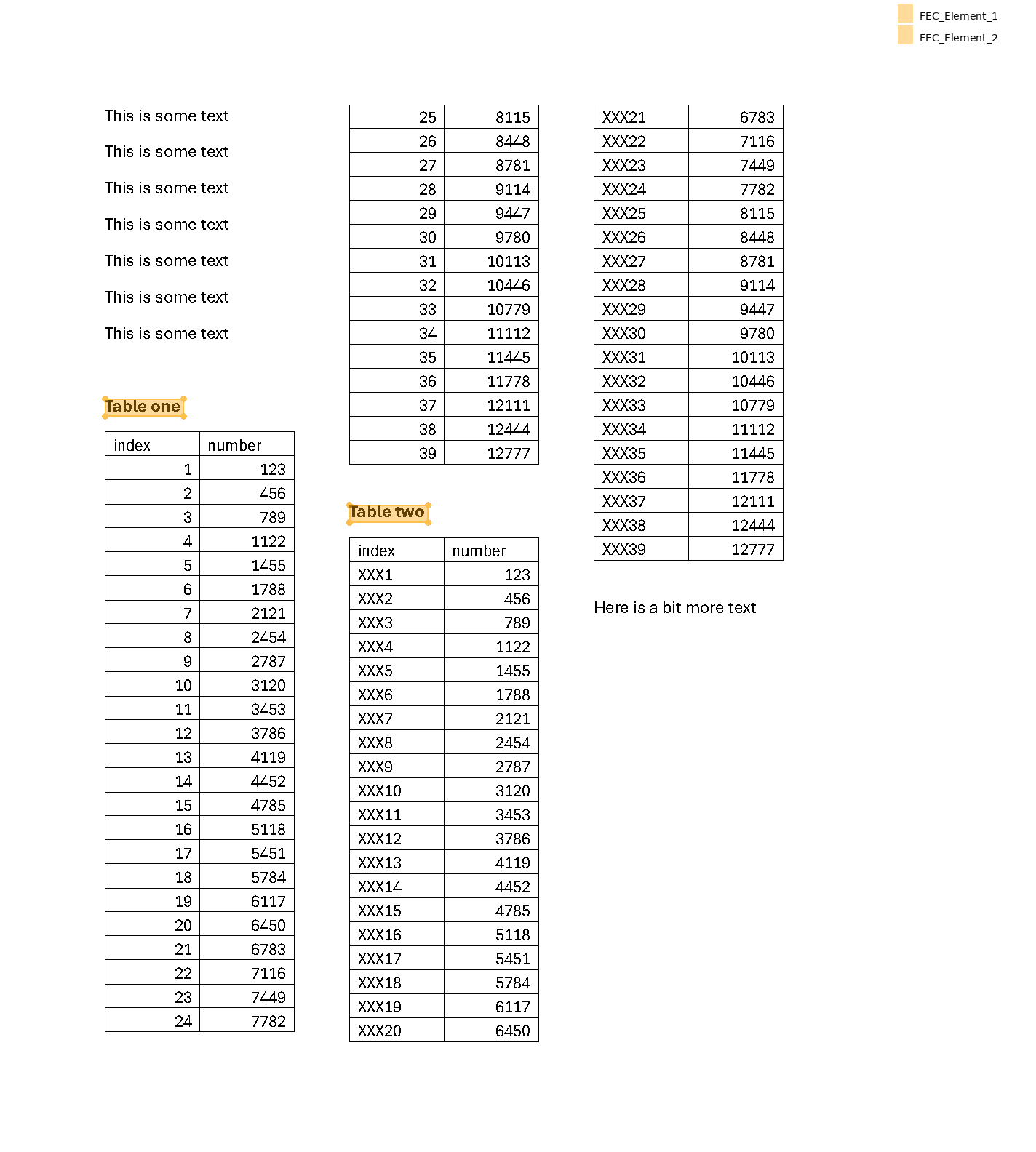
It works for text, it works for tables, it works for anything. Let's see how we can get both tables on the page.
First we find the bold headers – we need to say width > 10 because otherwise it pulls some weird tiny empty boxes.
(
flow
.find_all('text[width>10]:bold')
.show()
)
Then we take each of those headers, and go down down down until we either hit another bold header or the "Here is a bit more text" text.
regions = (
flow
.find_all('text[width>10]:bold')
.below(
until='text[width>10]:bold|text:contains("Here is a bit")',
include_endpoint=False
)
)
regions.show()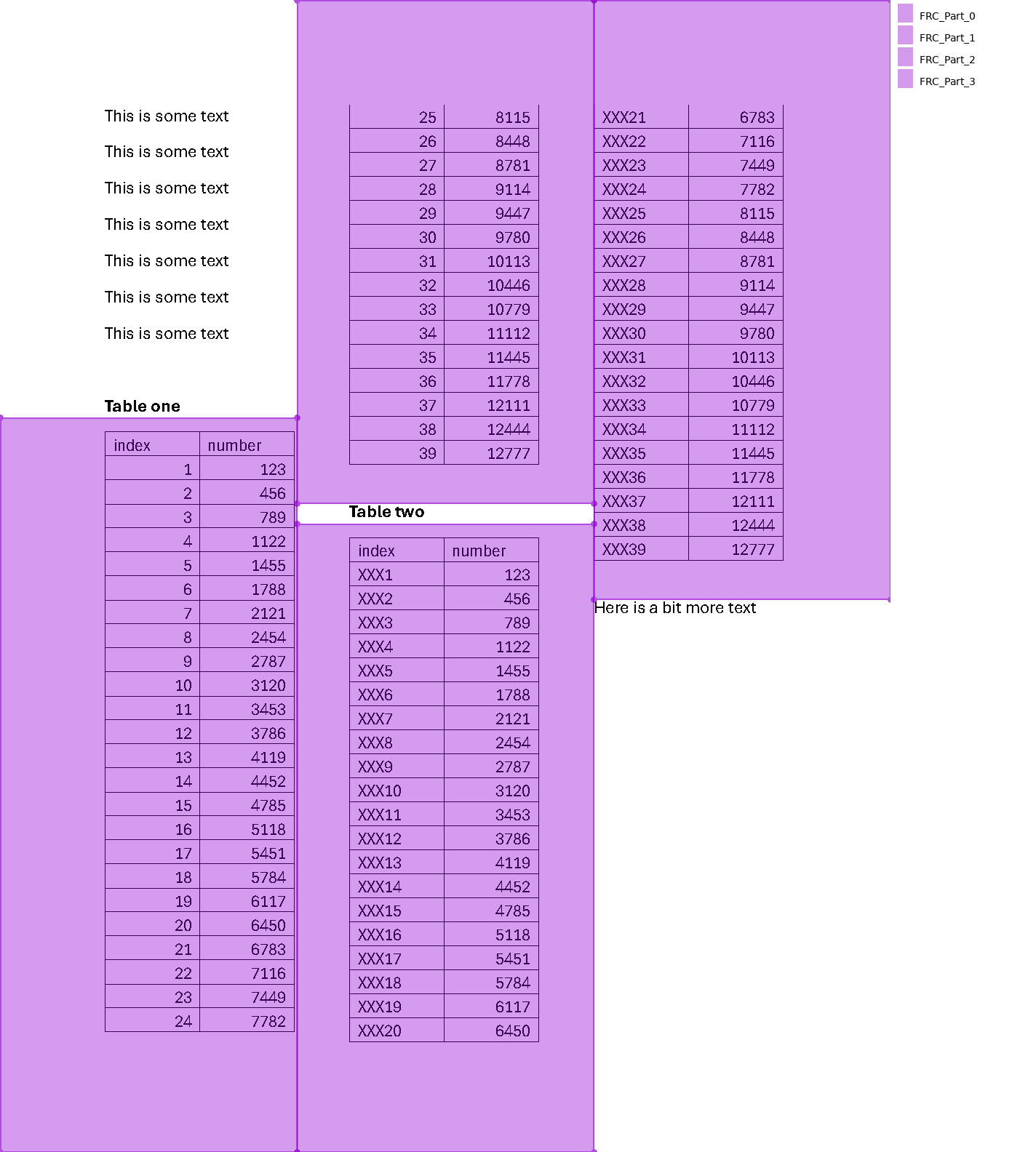
Now we can use .extract_table() on each individual region to give us however many tables.
regions[0].extract_table().to_df()| index | number | |
|---|---|---|
| 0 | 1 | 123 |
| 1 | 2 | 456 |
| 2 | 3 | 789 |
| 3 | 4 | 1122 |
| 4 | 5 | 1455 |
| 5 | 6 | 1788 |
| 6 | 7 | 2121 |
| 7 | 8 | 2454 |
| 8 | 9 | 2787 |
| 9 | 10 | 3120 |
| 10 | 11 | 3453 |
| 11 | 12 | 3786 |
| 12 | 13 | 4119 |
| 13 | 14 | 4452 |
| 14 | 15 | 4785 |
| 15 | 16 | 5118 |
| 16 | 17 | 5451 |
| 17 | 18 | 5784 |
| 18 | 19 | 6117 |
| 19 | 20 | 6450 |
| 20 | 21 | 6783 |
| 21 | 22 | 7116 |
| 22 | 23 | 7449 |
| 23 | 24 | 7782 |
| 24 | 26 | 8448 |
| 25 | 27 | 8781 |
| 26 | 28 | 9114 |
| 27 | 29 | 9447 |
| 28 | 30 | 9780 |
| 29 | 31 | 10113 |
| 30 | 32 | 10446 |
| 31 | 33 | 10779 |
| 32 | 34 | 11112 |
| 33 | 35 | 11445 |
| 34 | 36 | 11778 |
| 35 | 37 | 12111 |
| 36 | 38 | 12444 |
| 37 | 39 | 12777 |
# Combine them if we want
import pandas as pd
dfs = regions.apply(lambda region: region.extract_table().to_df())
merged = pd.concat(dfs, ignore_index=True)
merged| index | number | |
|---|---|---|
| 0 | 1 | 123 |
| 1 | 2 | 456 |
| 2 | 3 | 789 |
| 3 | 4 | 1122 |
| 4 | 5 | 1455 |
| ... | ... | ... |
| 71 | XXX35 | 11445 |
| 72 | XXX36 | 11778 |
| 73 | XXX37 | 12111 |
| 74 | XXX38 | 12444 |
| 75 | XXX39 | 12777 |
76 rows × 2 columns
Layout analysis and magic table extraction
Similar to how we have feelings about what things are on a page - headers, tables, graphics – computers also have opinions! Just like some AI models have been trained to do things like identify pictures of cats and dogs or spell check, others are capable of layout analysis - YOLO, surya, etc etc etc. There are a million! TATR is one of the useful ones for us, it's just for table detection.
But honestly: they're mostly trained on academic papers, so they aren't very good at the kinds of awful documents that journalists have to deal with. And with Natural PDF, you're probably selecting text[size>12]:bold in order to find headlines, anyway. But if your page has no readable text, they might be able to provide some useful information.
Let's start with YOLO, the default.
from natural_pdf import PDF
pdf = PDF("needs-ocr.pdf")
page = pdf.pages[0]# default is YOLO
page.analyze_layout()
page.find_all('region').show(group_by='type')image 1/1 /tmp/tmpp63fsg8k/temp_layout_image.png: 1024x800 2 titles, 3 plain texts, 2 abandons, 1 table, 1667.0ms Speed: 4.5ms preprocess, 1667.0ms inference, 2.1ms postprocess per image at shape (1, 3, 1024, 800)

page.find('table').apply_ocr()
text = page.extract_text()
print(text)Statute Description Level Repeat? 4.12.7 Unsanitary Working Conditions. Critical 5.8.3 Inadequate Protective Equipment: Serious 6.3.9 Ineffective Injury Prevention Serious 7.1.5 Failure to Properly Store Hazardous Materials: Critical 8.9.2 Lack of Adequate Fire Safety Measures. Serious 9.6.4 Inadequate Ventilation Systems. Serious 10.2.7 Insufficient Employee Training for Safe Work Practices_ Serious Using CPU. Note: This module is much faster with a GPU. /home/runner/work/badpdfs-site/badpdfs-site/processor/.venv/lib/python3.11/site-packages/torch/utils/data/dataloader.py:666: UserWarning: 'pin_memory' argument is set as true but no accelerator is found, then device pinned memory won't be used. warnings.warn(warn_msg)
Better layout analysis with tables
Let's see what TATR - Microsoft's table transformer – finds for us.
page.analyze_layout('tatr')
page.find_all('region').show(group_by='type')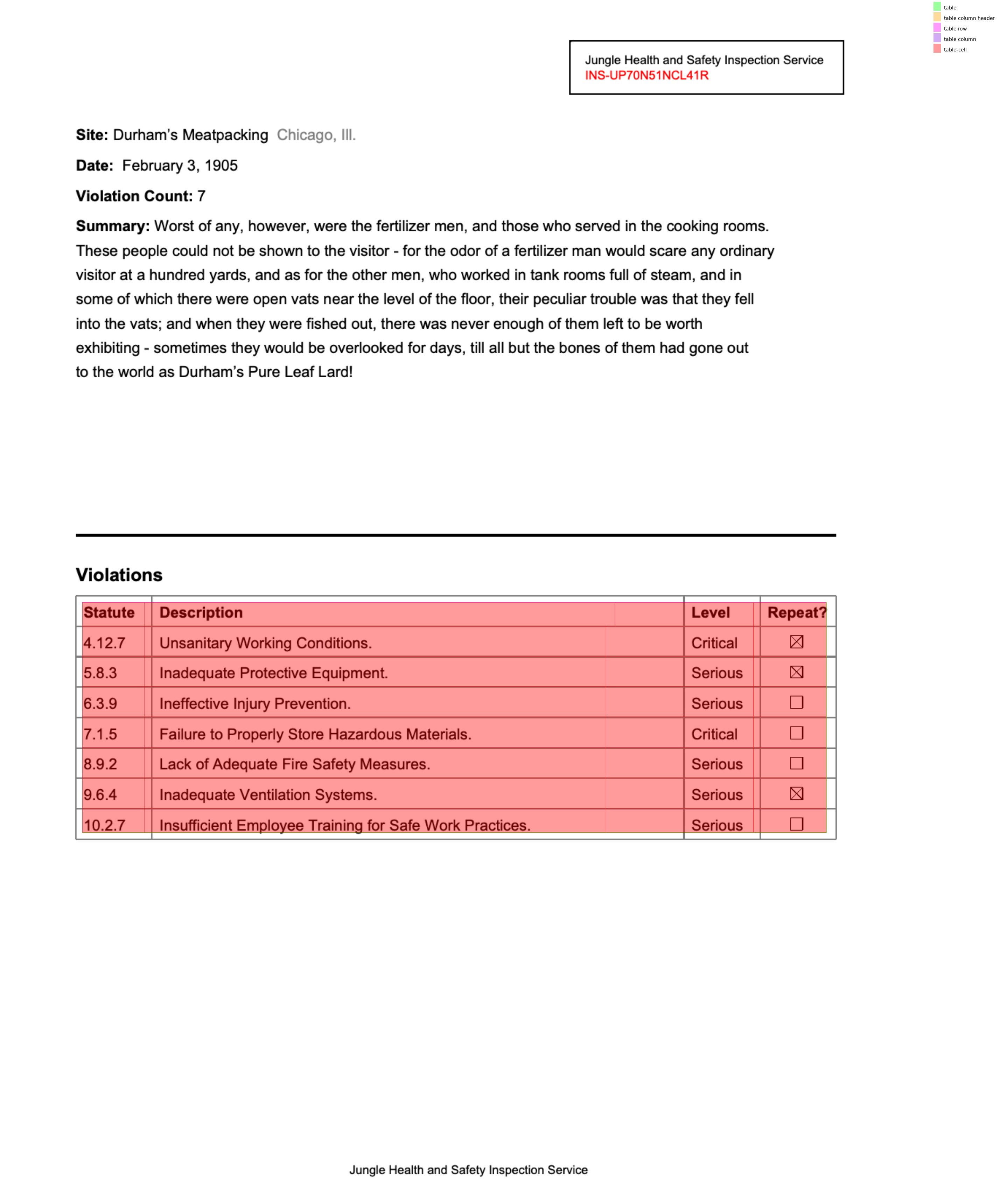
There's just so much stuff that TATR is finding that it's all overlapping.
For example, we can just look at one piece at a time.
# table-cell
# table-row
# table-column
page.find_all('region[type=table-column]').show(crop=True)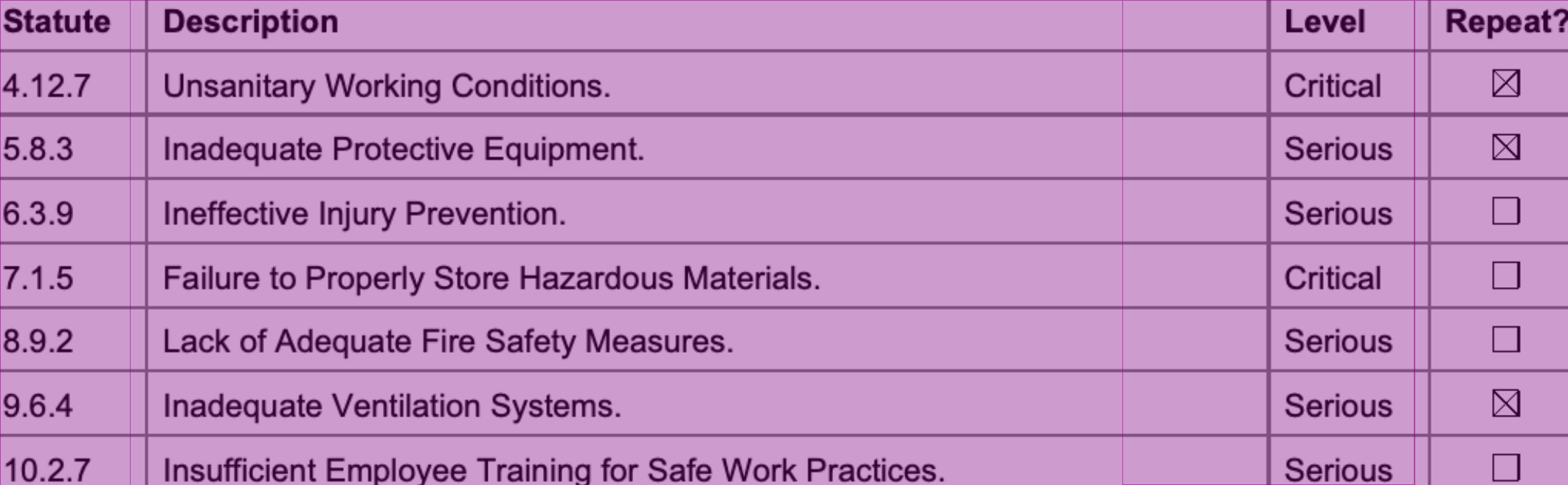
# Grab all of the columns
cols = page.find_all('region[type=table-column]')
# Take one of the columns and apply OCR to it
cols[2].apply_ocr()
text = cols[2].extract_text()
print(text)Level Critical Serious Serious Critical Serious Serious Serious
len(cols[2].find_all('text[source=ocr]'))8
page.find('table').show()
data = page.find('table').extract_table()
dataTableResult(rows=9…)
Why YOLO?
I think YOLO is pretty good for isolating a part of a page that has a table, then using Guides to break it down.
page.analyze_layout()
page.find_all('region').show(group_by="type")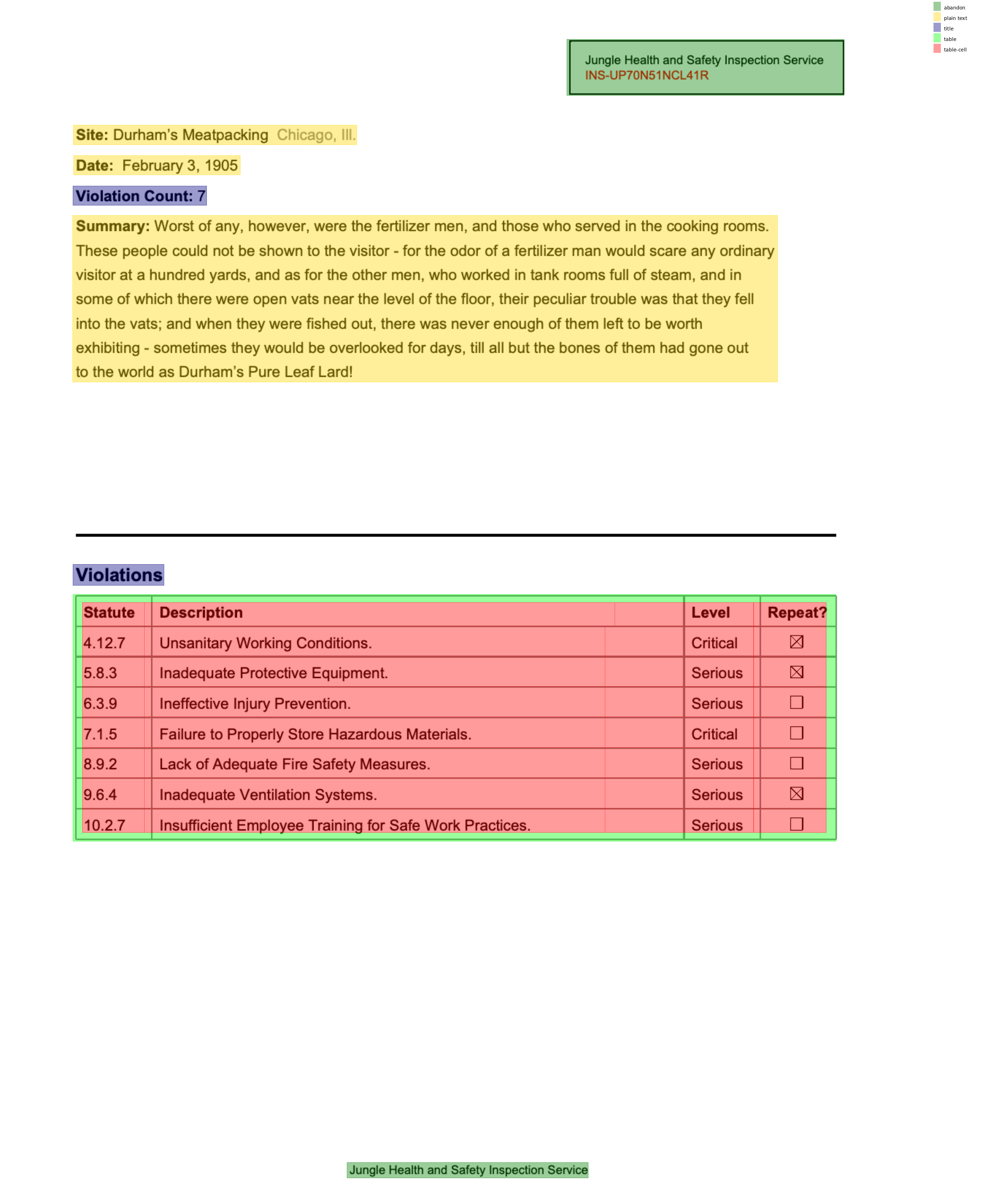
table_area = page.find("region[type=table]")
table_area.apply_ocr()<Region type='table' source='detected' bbox=(99.85877990722656, 815.1997680664062, 1146.6968994140625, 1153.8369140625)>
text = table_area.extract_text()
print(text)Statute Description Level Repeat? 4.12.7 Unsanitary Working Conditions. Critical 5.8.3 Inadequate Protective Equipment: Serious 6.3.9 Ineffective Injury Prevention Serious 7.1.5 Failure to Properly Store Hazardous Materials: Critical 8.9.2 Lack of Adequate Fire Safety Measures. Serious 9.6.4 Inadequate Ventilation Systems. Serious 10.2.7 Insufficient Employee Training for Safe Work Practices_ Serious
from natural_pdf.analyzers import Guides
guides = Guides(table_area)
guides.vertical.from_lines(threshold=0.6)
guides.horizontal.from_lines(threshold=0.6)
guides.show()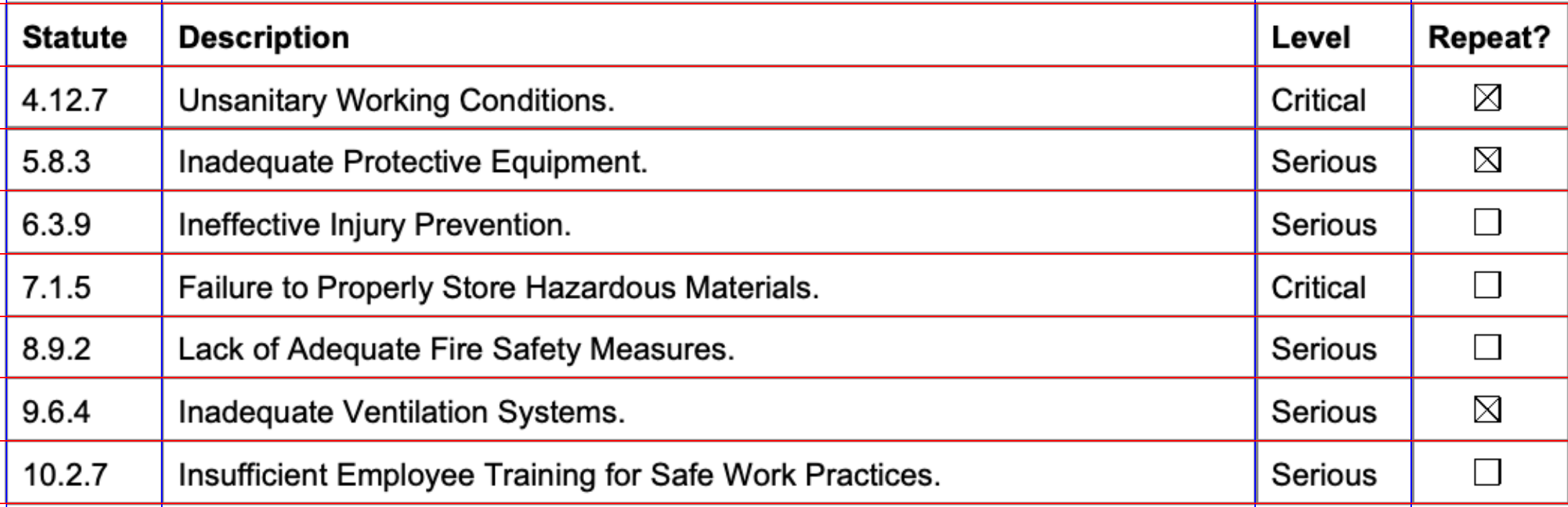
guides.extract_table().to_df()| Statute | Description | Level | |
|---|---|---|---|
| 0 | 4.12.7 | Unsanitary Working Conditions. | Critical |
| 1 | 5.8.3 | Inadequate Protective Equipment: | Serious |
| 2 | 6.3.9 | Ineffective Injury Prevention | Serious |
| 3 | 7.1.5 | Failure to Properly Store Hazardous Materials: | Critical |
| 4 | 8.9.2 | Lack of Adequate Fire Safety Measures. | Serious |
| 5 | 9.6.4 | Inadequate Ventilation Systems. | Serious |
| 6 | 10.2.7 | Insufficient Employee Training for Safe Work P... | Serious |