
Extracting Complex Data from Serbian Regulatory PDF
This PDF contains parts of Serbian policy documents, crucial for a research project analyzing industry policies across countries. The challenge lies in extracting a large table that spans pages (page 90 to 97) and a math formula on page 98, all in Serbian. Both elements lack clear boundaries between pages, complicating extraction.
from natural_pdf import PDF
from natural_pdf.analyzers.guides import Guides
pdf = PDF("serbia-zakon-o-naknadama-za-koriscenje-javnih.pdf")
pdf.pages[:8].show(cols=4)
The submitter mentioned specific pages, but it's more fun to say "between the page with this and the page with that."
first_page = pdf.find(text="Prilog 7.").page
last_page = pdf.find(text='VISINA NAKNADE ZA ZAGAĐENJE VODA').page
pages = pdf.pages[first_page.index:last_page.index+1]
pages.show(cols=4)
We want everything between Table 4 and 5.
region = (
pages
.find(text="Tabela 4")
.below(
until="text:contains(Tabela 5)",
include_endpoint=False,
multipage=True
)
)
region.show(cols=4)
We want everything broken up by category, which is labeled as "RAZRED" in the document. We'll just split it into sections with those serving as headers.
sections = region.get_sections('text:contains(RAZRED)', include_boundaries='none')
sections.show(cols=4)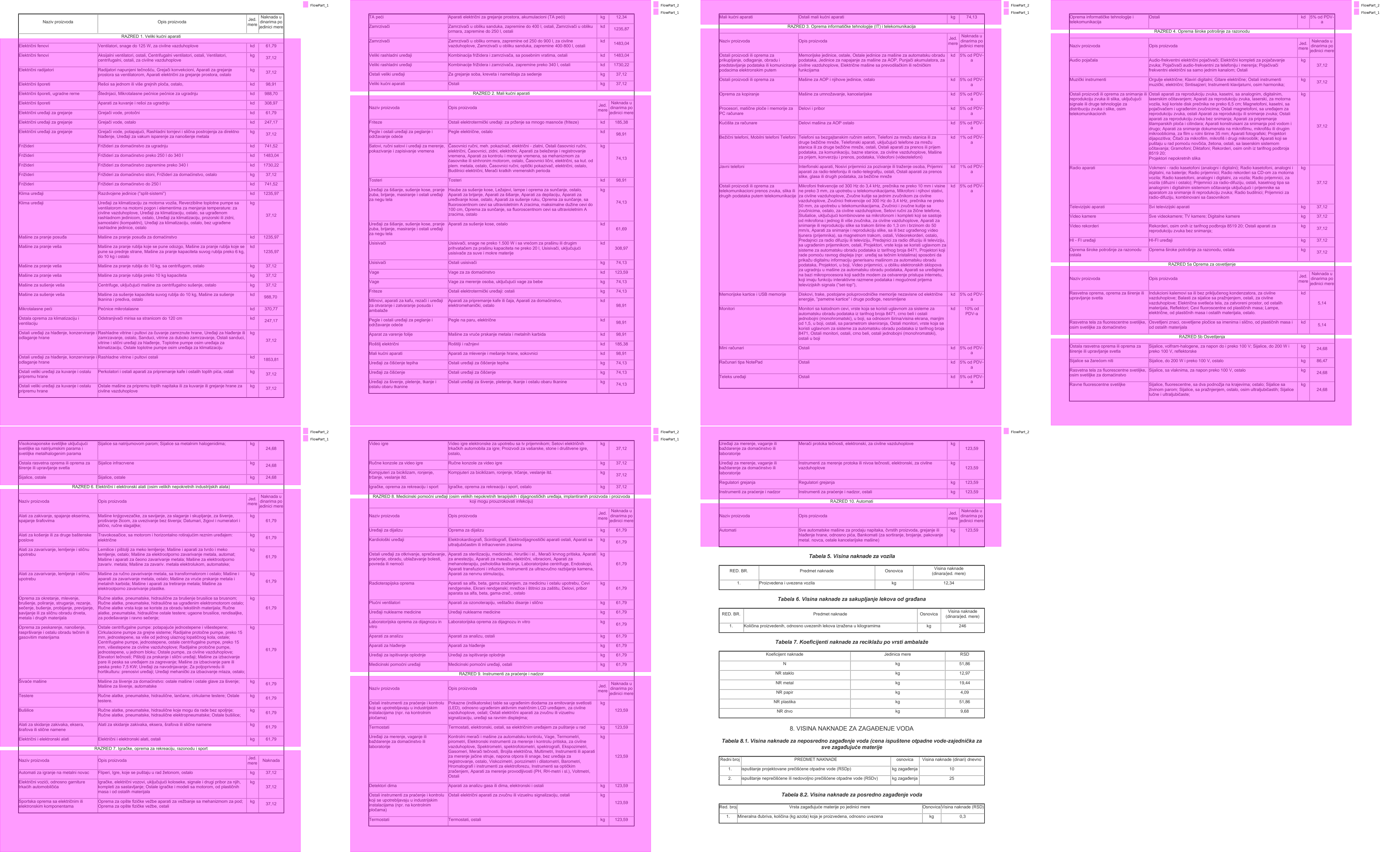
Some of them have headers and some of them don't, which can make extraction tough. Here's one that spans two pages and has headers.
sections[7].show(cols=2)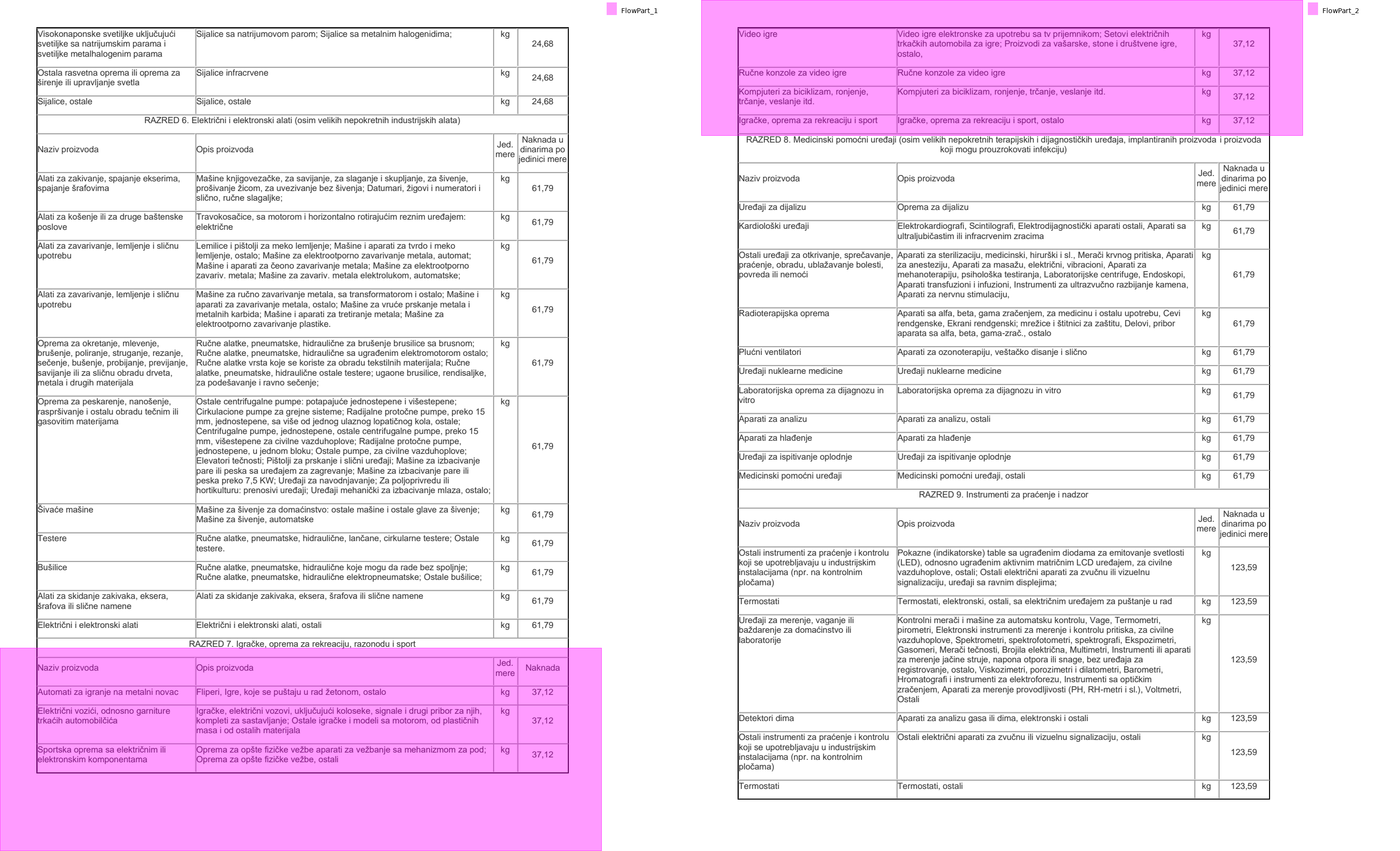
Since it has headers, we can just use .to_df().
sections[7].extract_table().to_df()| Naziv proizvoda | Opis proizvoda | Jed.\nmere | Naknada | |
|---|---|---|---|---|
| 0 | Automati za igranje na metalni novac | Fliperi, Igre, koje se puštaju u rad žetonom, ... | kg | 37,12 |
| 1 | Električni vozići, odnosno garniture\ntrkaćih ... | Igračke, električni vozovi, uključujući kolose... | kg | 37,12 |
| 2 | Sportska oprema sa električnim ili\nelektronsk... | Oprema za opšte fizičke vežbe aparati za vežba... | kg | 37,12 |
| 3 | Video igre | Video igre elektronske za upotrebu sa tv prije... | kg | 37,12 |
| 4 | Ručne konzole za video igre | Ručne konzole za video igre | kg | 37,12 |
| 5 | Kompjuteri za biciklizam, ronjenje,\ntrčanje, ... | Kompjuteri za biciklizam, ronjenje, trčanje, v... | kg | 37,12 |
| 6 | Igračke, oprema za rekreaciju i sport | Igračke, oprema za rekreaciju i sport, ostalo | kg | 37,12 |
This next one does not have headers.
sections[5].show(cols=2)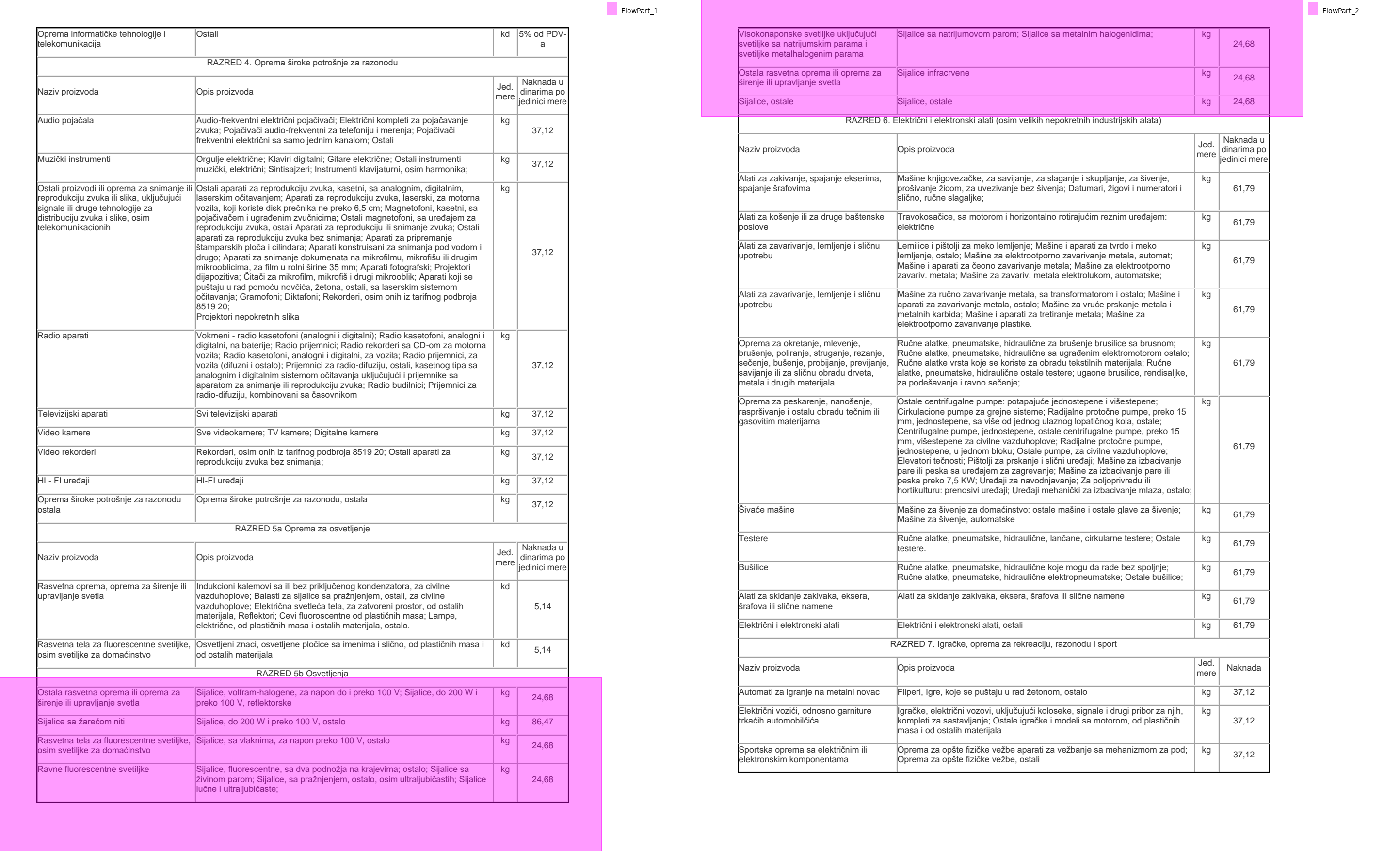
We'll just manually specify them, probably the easiest route.
df = sections[5].extract_table().to_df(header=False)
df.columns = ['Naziv proizvoda', 'Opis proizvoda', 'Jed. mere', 'Naknada u dinarima po jedinici mere']
df| Naziv proizvoda | Opis proizvoda | Jed. mere | Naknada u dinarima po jedinici mere | |
|---|---|---|---|---|
| 0 | Ostala rasvetna oprema ili oprema za\nširenje ... | Sijalice, volfram-halogene, za napon do i prek... | kg | 24,68 |
| 1 | Sijalice sa žarećom niti | Sijalice, do 200 W i preko 100 V, ostalo | kg | 86,47 |
| 2 | Rasvetna tela za fluorescentne svetiljke,\nosi... | Sijalice, sa vlaknima, za napon preko 100 V, o... | kg | 24,68 |
| 3 | Ravne fluorescentne svetiljke | Sijalice, fluorescentne, sa dva podnožja na kr... | kg | 24,68 |
| 4 | Visokonaponske svetiljke uključujući\nsvetiljk... | Sijalice sa natrijumovom parom; Sijalice sa me... | kg | 24,68 |
| 5 | Ostala rasvetna oprema ili oprema za\nširenje ... | Sijalice infracrvene | kg | 24,68 |
| 6 | Sijalice, ostale | Sijalice, ostale | kg | 24,68 |
How do we find the math formula? Find the page that has it, then just ask for the image.
page = pdf.find(text="Obračun naknade za neposredno zagađenje voda").page
page.find("image").show()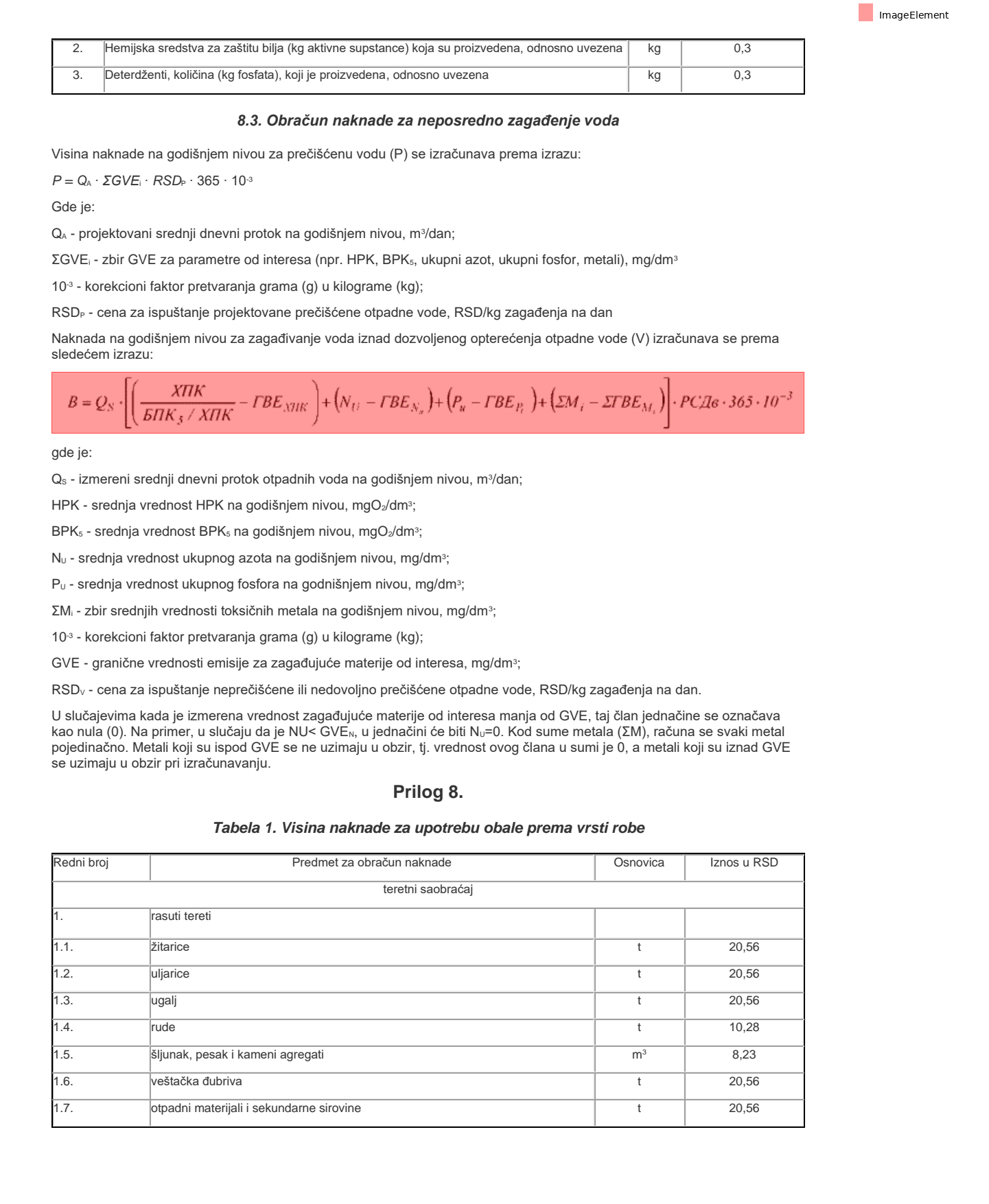
If we were fancier we'd probably use surya to convert it, but Natural PDF can't extract images like that just yet (I don't think?).