Extracting Data Tables from Oklahoma Booze Licensees PDF
This PDF contains detailed tables listing alcohol licensees in Oklahoma. It has zebra-striped, multi-line cells without lines, making it hard to extract data accurately.
...or is that helpful?
from natural_pdf import PDF
pdf = PDF("m27.pdf")
page = pdf.pages[0]
page.show()
Exclusions
First let's think about what we don't want: headers and footers.
header = page.find(text="PREMISE").above()
footer = page.find("text:regex(Page \d+ of)")
(header + footer).show()
To make exclusions apply to each page instead of just your current page, you can use lambda page: page.xxx.
print("Before exclusions:", page.extract_text()[:200])
# Add exclusions
pdf.add_exclusion(lambda page: page.find(text="PREMISE").above())
pdf.add_exclusion(lambda page: page.find("text:regex(Page \d+ of)").expand())
print("After exclusions:", page.extract_text()[:200])
# Preview
page.show(exclusions='red')Before exclusions: FEBRUARY 2014 M27 (BUS) ALPHABETIC LISTING BY TYPE ABLPDM27 OF ACTIVE LICENSES 3/19/2014 OKLAHOMA ABLE COMMISSION LICENSE PREMISE NUMBER TYPE DBA NAME LICENSEE NAME ADDRESS CITY ST ZIP PHONE NUMBER EX After exclusions: LICENSE PREMISE NUMBER TYPE DBA NAME LICENSEE NAME ADDRESS CITY ST ZIP PHONE NUMBER EXPIRES 648765 AAA ALLEGIANT AIR ALLEGIANT AIR LLC 7100 TERMINAL DRIVE OKLAHOMA CITY OK 73159 - 2014/12/03 7777 EAST
Table extraction
A basic page.extract_table() won't work – spacing is too narrow, not enough details – so we'll use guides to extract the table.
from natural_pdf.analyzers.guides import Guides
guides = Guides(page)Table columns
We'll start by creating some lines to separate each column. It's easiest to grab the "NUMBER" header and then everything to the right of it.
region = (
page
.find(text="NUMBER")
.right(include_source=True)
)
region.show(crop=100)
When we grab each header we need a little 3px wiggle room, as the lines aren't exactly lined up.
headers = (
page
.find(text="NUMBER")
.right(include_source=True)
.expand(top=3, bottom=3)
.find_all('text')
)
headers.show(crop=100)
Notice how all of the headers are left-aligned? We can use that to build a grid with our guides.
guides.vertical.from_content(headers, align='left')
guides.show()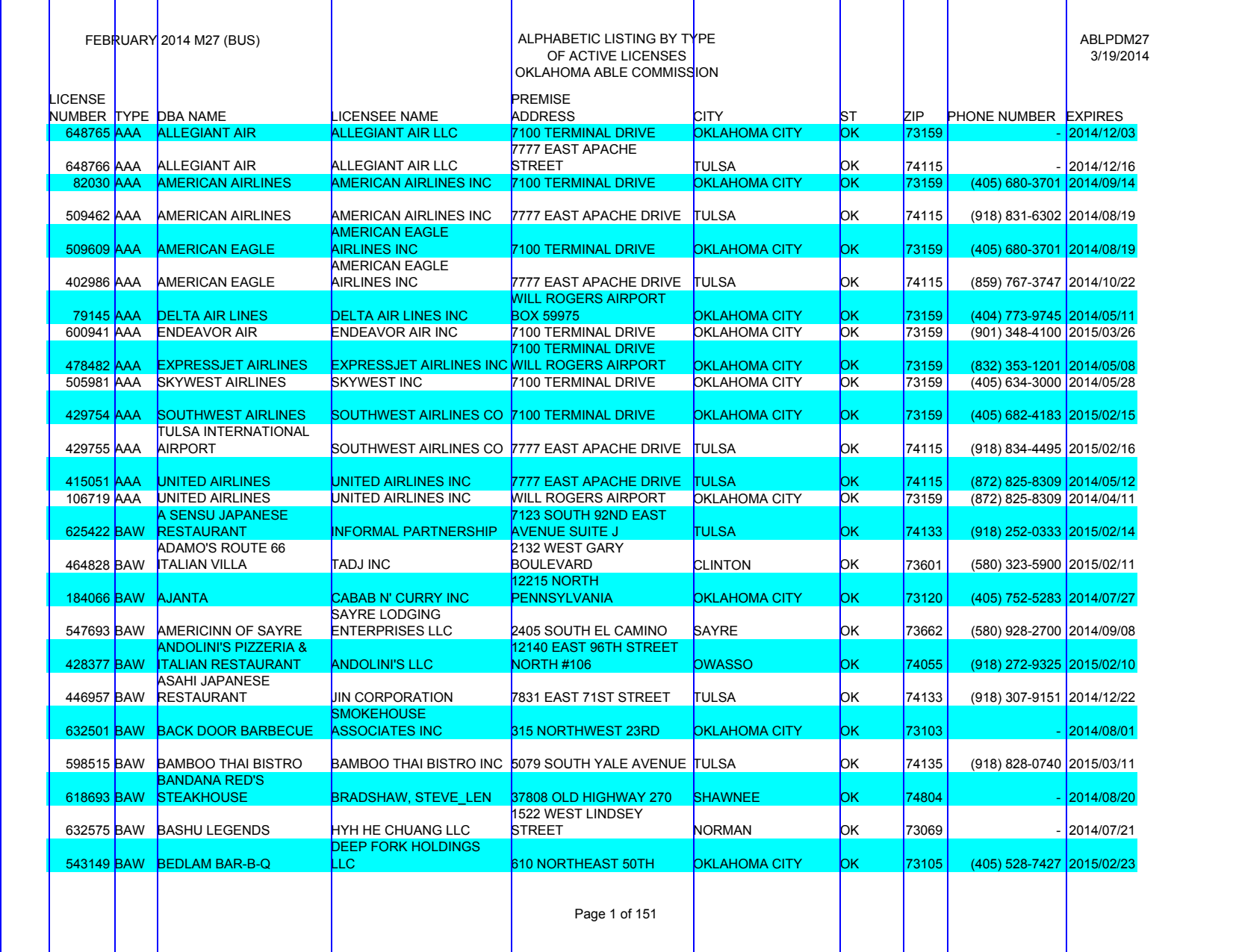
Now we need to separate out our rows: we have two options!
Rows have alternating blue bands behind them. If we use horizontal.from_stripes() it will go through a two-step process:
- Find the most popular color rectangles
- Add guidelines for the top and bottom of each rectangle
You can also set the color= or find+pass the rectangles yourself, but in this case it works with the default options.
guides.horizontal.from_stripes()
guides.show()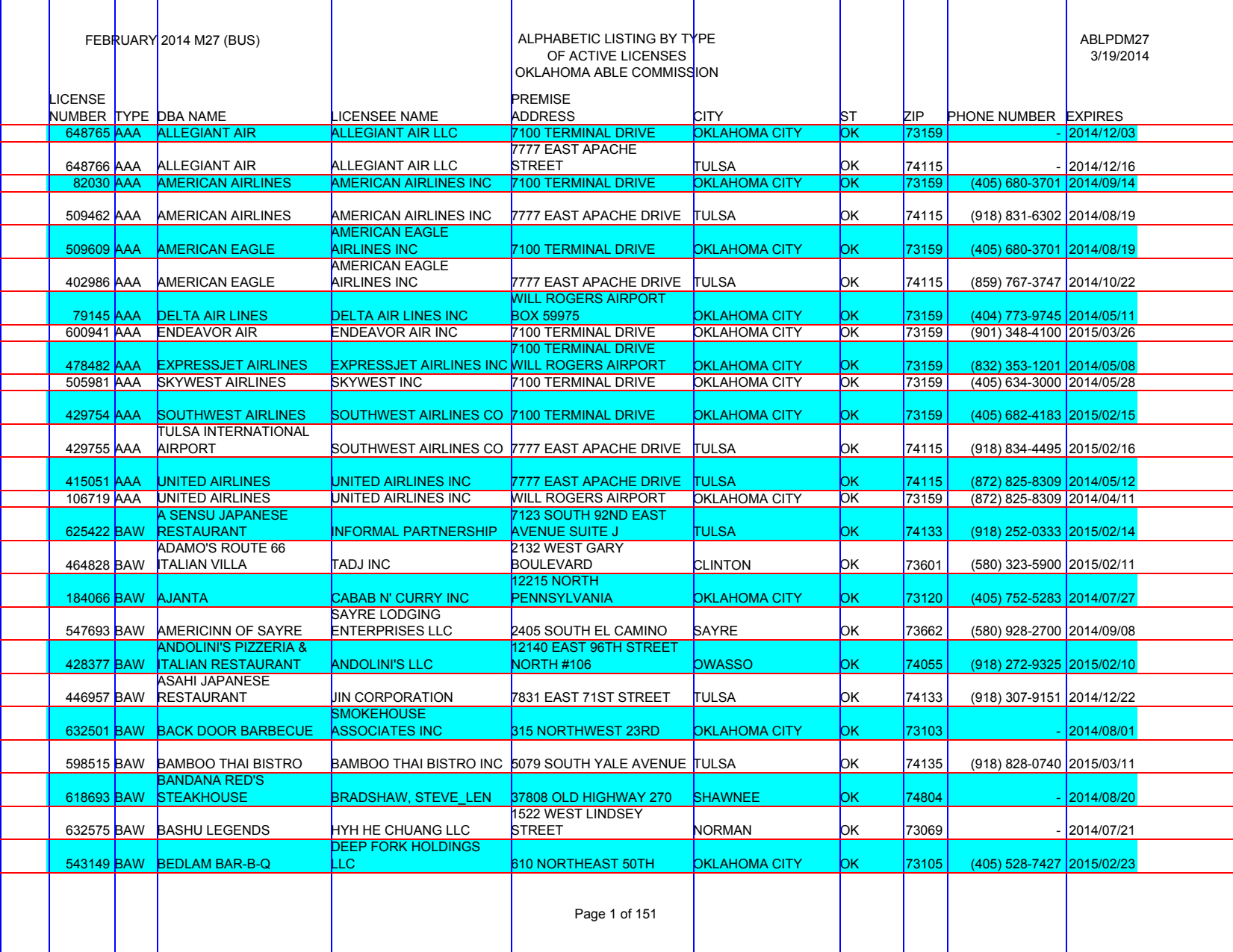
Instead of relying on the colored banding, we can also find an item that shows up exactly once in each row, then use that to draw the borders.
(
page
.find(text="NUMBER")
.below(width='element')
).show(crop=100, width=700)
We draw down from the NUMBER header, then find all of the elements under it. We do need to ask for overlap='partial' because the header doesn't fully encompass each license number.
rows = (
page
.find(text="NUMBER")
.below(
width='element',
include_source=True
)
.find_all('text', overlap='partial')
)
rows.show(crop=100, width=700)
Now we can feed each row to from_content and tell Natural PDF to draw a border at the bottom of each one.
guides.horizontal.from_content(rows, align='bottom')
guides.show()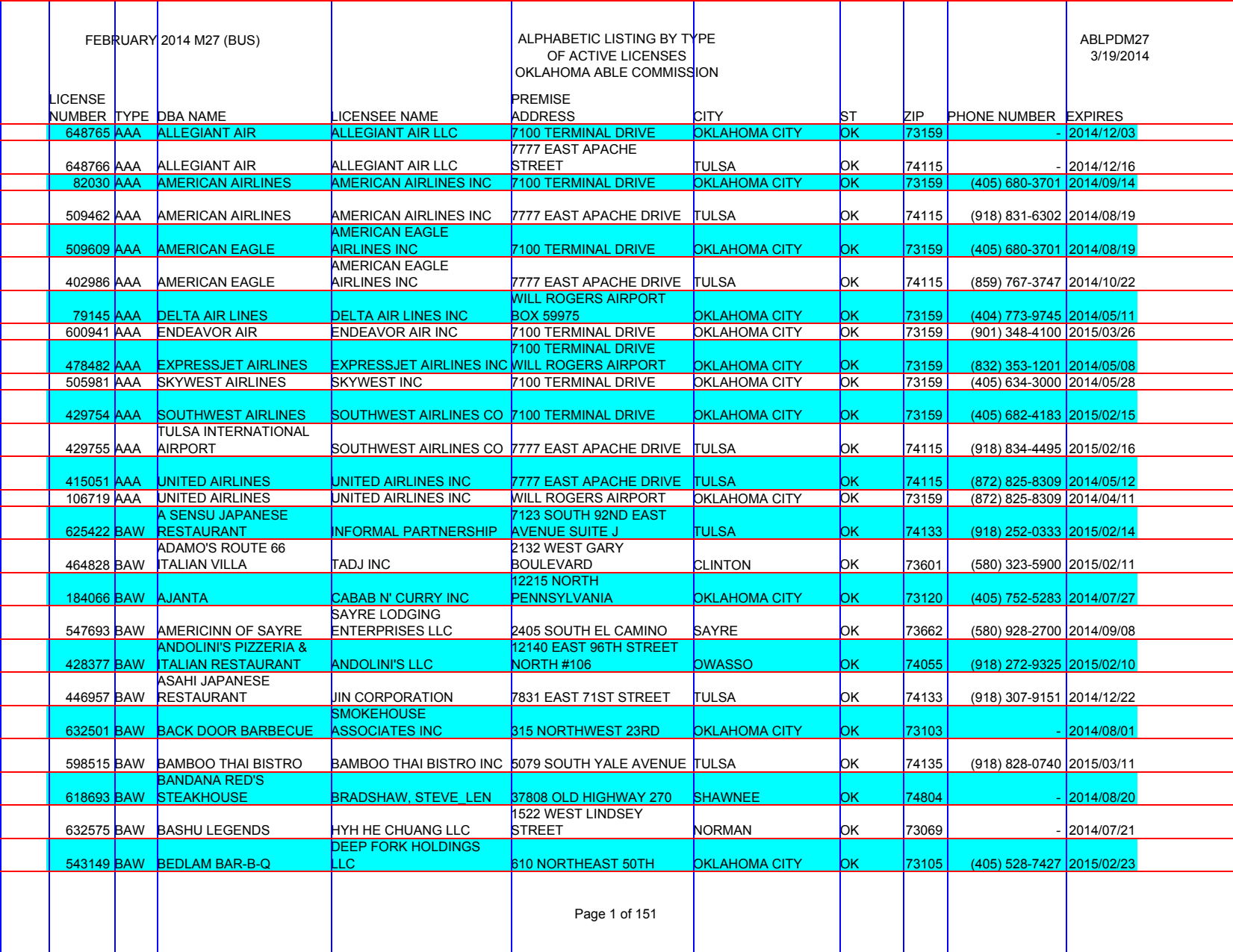
Depending on how you set up your extraction, include_outer_boundaries=True isn't necessarily necessary, but I'm using it here so that it works for both approaches up above (even though one gives you an extra column).
df = (
guides
.extract_table(include_outer_boundaries=True)
.to_df()
)
df.head()| None | LICENSE\nNUMBER | TYPE | DBA NAME | LICENSEE NAME | PREMISE\nADDRESS | CITY | ST | ZIP | PHONE NUMBER | EXPIRES | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | 648765 | AAA | ALLEGIANT AIR | ALLEGIANT AIR LLC | 7100 TERMINAL DRIVE | OKLAHOMA CITY | OK | 73159 | - | 2014/12/03 |
| 1 | None | 648766 | AAA | ALLEGIANT AIR | ALLEGIANT AIR LLC | 7777 EAST APACHE\nSTREET | TULSA | OK | 74115 | - | 2014/12/16 |
| 2 | None | 82030 | AAA | AMERICAN AIRLINES | AMERICAN AIRLINES INC | 7100 TERMINAL DRIVE | OKLAHOMA CITY | OK | 73159 | (405) 680-3701 | 2014/09/14 |
| 3 | None | 509462 | AAA | AMERICAN AIRLINES | AMERICAN AIRLINES INC | 7777 EAST APACHE DRIVE | TULSA | OK | 74115 | (918) 831-6302 | 2014/08/19 |
| 4 | None | 509609 | AAA | AMERICAN EAGLE | AMERICAN EAGLE\nAIRLINES INC | 7100 TERMINAL DRIVE | OKLAHOMA CITY | OK | 73159 | (405) 680-3701 | 2014/08/19 |