
Animal 911 Calls Extraction from Rainforest Cafe Report
This PDF is a service call report covering 911 incidents at the Rainforest Cafe in Niagara Falls, NY. We're hunting for animals! The data is formatted as a spreadsheet within the PDF, and challenges include varied column widths, borderless tables, and large swaths of missing data.
from natural_pdf import PDF
pdf = PDF("24480polcompleted.pdf")
pdf.show(cols=3, limit=9)
Selecting a subset of pages
We only want the spreadsheet pages, which start on page 5.
pages = pdf.pages[4:]
pages.show(cols=6)
Excluding extra text
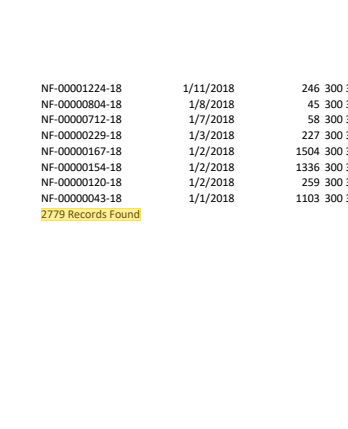
If we look at the last page we see "2770 Records Found" at the bottom of the table, which we do not want in our dataset.
pages[-1].show(crop=200)
We're going to exclude it so it doesn't show up in our table or confuse the table detector. But instead of matching it exactly, what if we end up doing this with different sets of documents? Maybe across years? It's easier to match with a regex, so instead of a specific number of records found we can look for ____ Records Found.
(
pages[-1]
.find_all('text:regex(\\d+ Records Found)')
.show(crop=100)
)
Anything we can find we can exclude. Depending on what we expect our data to look like, we can exclude two different ways.
We know the "XXX results" will always be on the last page, so we can add a simple text selector match.
pages[-1].add_exclusion('text:regex(\\d+ Records Found)')<Page number=47 index=46>
If we aren't sure whether the record counts will be on other pages besides the last page, we can add it to the PDF. This will apply it to every single page.
pdf.add_exclusion(
lambda page: page.find_all('text:regex(\\d+ Records Found)')
)<PDF source='24480polcompleted.pdf' pages=47>
Record counts: excluded!
pages[-1].show(exclusions='red')
Building our table
Now we need to build our table. Let's take a look at what the first page looks like again.
pages[0].show()
Extracting the tables with guides
We're going to use guides to outline the table with the following steps:
- Drop vertical lines between the column headers, then re-use these boundaries on each page.
- For horizontal rows, we'll say find every place where text starts with NF-, since each row starts with
NF-00051026-24. That way even if there are multi-line rows we shouldn't have a problem.
There are two ways to do this: re-useable guides with lambdas or just manually updating your guide in a for loop.
You could probably do a raw
.extract_table()on each page and combine them, but using grids makes things a bit more specific and controlled.For example, if an entire column is empty on one page the "normal" extraction method won't understand that it's missing data. If you base your guides off of a full/complete page, though, it knows the empty area represents a column with missing data.
We'll start by using Guides to draw our boundaries. While we might be able to separate rows based on whitespace, it's easier to base the borders on the content of the page:
- Vertical boundaries go at the start of each of the column headers
- Each row is located by text that starts with
NF-
By default the last column (Main Officer) would be ignored since it doesn't have an "ending" vertical bar. To fix that I'll add outer="last" so the outer area after the last boundary counts as a column.
from natural_pdf.analyzers.guides import Guides
guide = Guides(pages[0])
columns = ['Number', 'Date Occurred', 'Time Occurred', 'Location', 'Call Type', 'Description', 'Disposition', 'Main Officer']
guide.vertical.from_content(columns, outer="last")
guide.horizontal.from_content(
lambda p: p.find_all('text:starts-with(NF-)')
)
guide.show()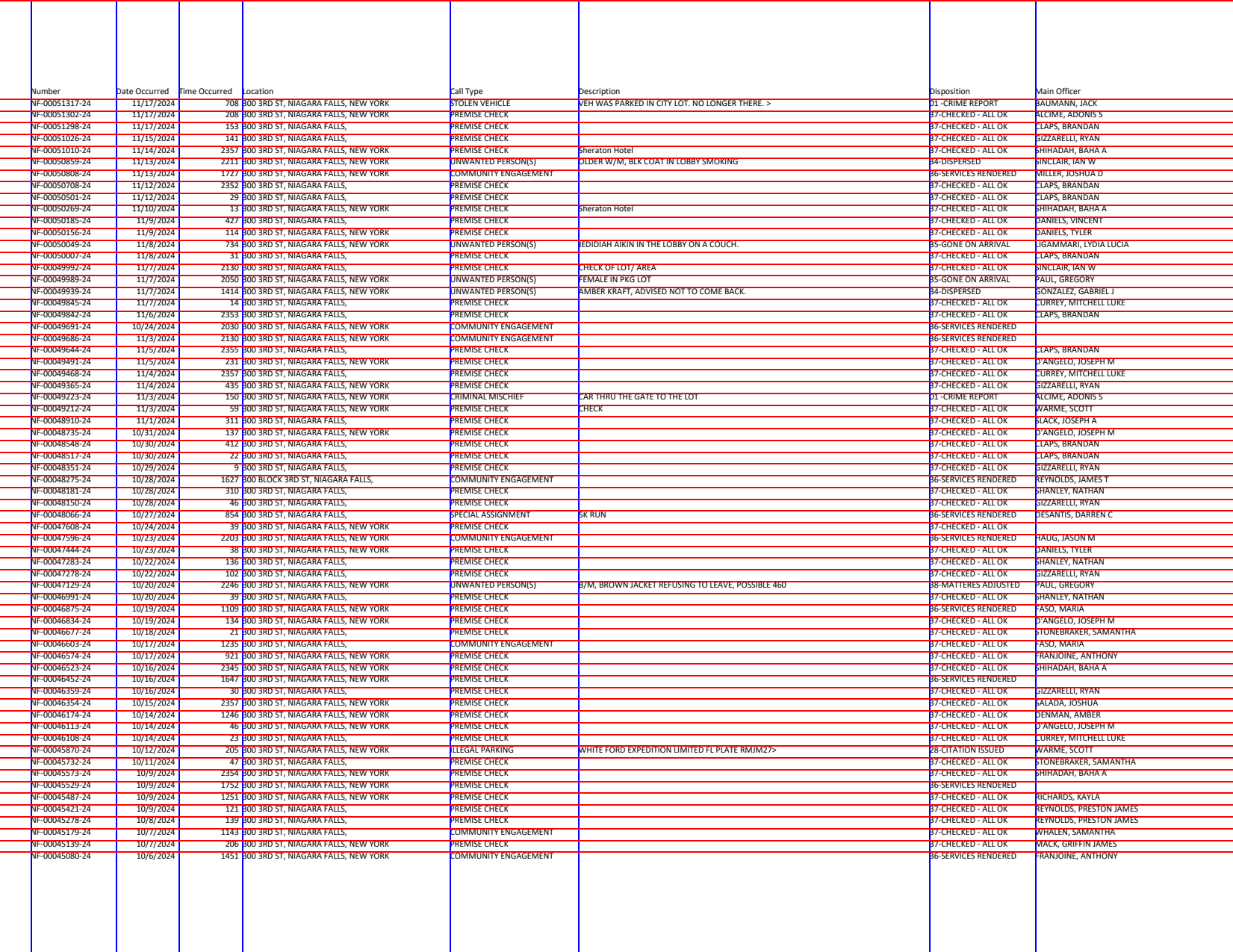
Notice how we used a lambda in the approach above. This means we don't just want the NF- content on the first page, we want it for any page the guide is applied to.
We then say, apply this guide to every single page! Since the headers are only on the first page, we use header="first".
table_result = guide.extract_table(pages, header="first")
df = table_result.to_df()
df.head()| Number | Date Occurred | Time Occurred | Location | Call Type | Description | Disposition | Main Officer | |
|---|---|---|---|---|---|---|---|---|
| 0 | NF-00051317-24 | 11/17/2024 | 708 | 300 3RD ST, NIAGARA FALLS, NEW YORK | STOLEN VEHICLE | VEH WAS PARKED IN CITY LOT. NO LONGER THERE. > | 01 -CRIME REPORT | BAUMANN, JACK |
| 1 | NF-00051302-24 | 11/17/2024 | 208 | 300 3RD ST, NIAGARA FALLS, NEW YORK | PREMISE CHECK | None | 37-CHECKED - ALL OK | ALCIME, ADONIS S |
| 2 | NF-00051298-24 | 11/17/2024 | 153 | 300 3RD ST, NIAGARA FALLS, | PREMISE CHECK | None | 37-CHECKED - ALL OK | CLAPS, BRANDAN |
| 3 | NF-00051026-24 | 11/15/2024 | 141 | 300 3RD ST, NIAGARA FALLS, | PREMISE CHECK | None | 37-CHECKED - ALL OK | GIZZARELLI, RYAN |
| 4 | NF-00051010-24 | 11/14/2024 | 2357 | 300 3RD ST, NIAGARA FALLS, NEW YORK | PREMISE CHECK | Sheraton Hotel | 37-CHECKED - ALL OK | SHIHADAH, BAHA A |
We'll start by drawing boundaries at the start of each of the column headers. Since there isn't a boundary to the right of the last column, we'll say outer="last" to have the outer area after the last boundary count as a column.
from natural_pdf.analyzers.guides import Guides
base = Guides(pages[0])
columns = ['Number', 'Date Occurred', 'Time Occurred', 'Location', 'Call Type', 'Description', 'Disposition', 'Main Officer']
base.vertical.from_content(columns, outer="last")
base.horizontal.from_content(pages[0].find_all('text:starts-with(NF-)'))
base.show()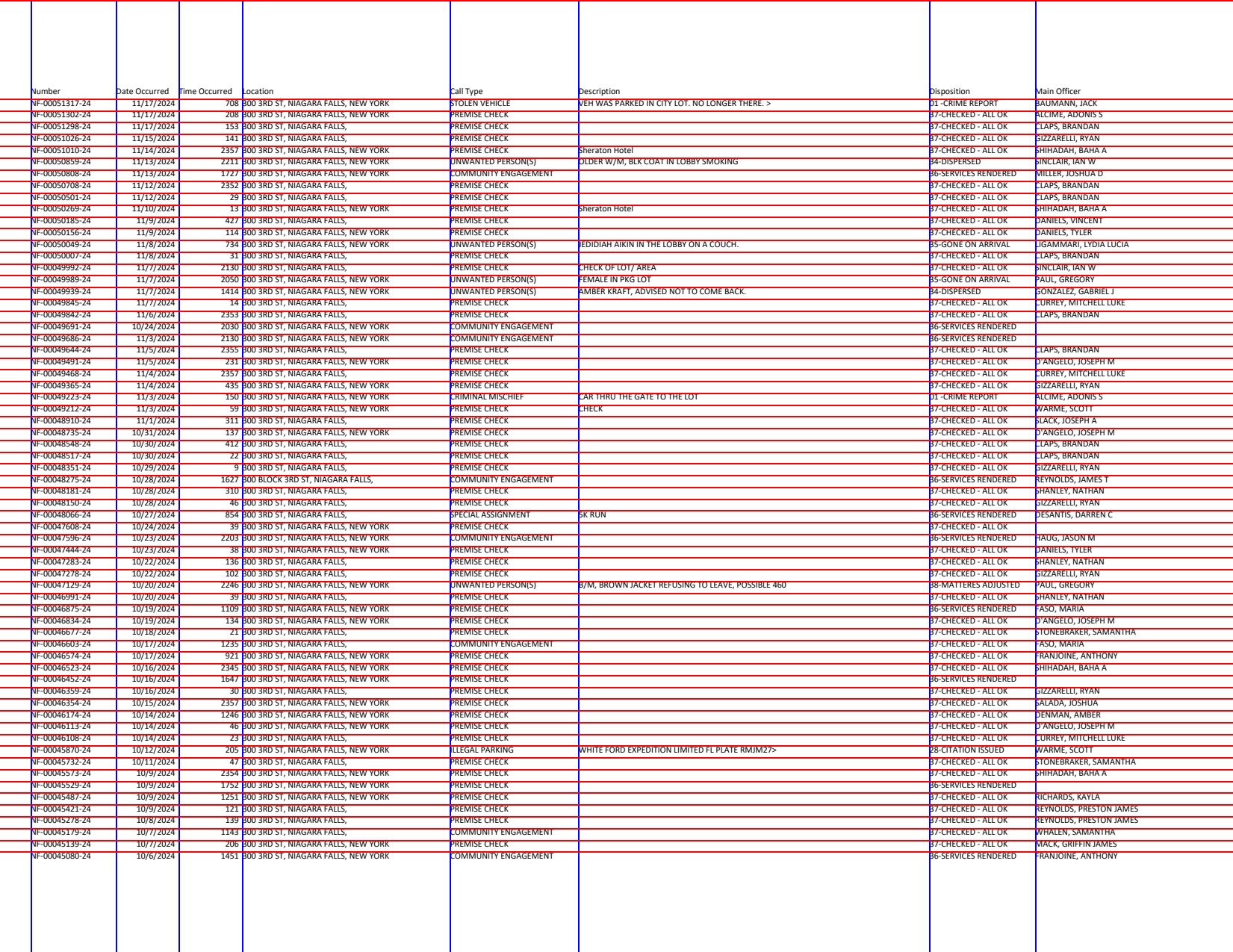
We'll then pull out the first table from the first page.
first_table = base.extract_table().to_df()
first_table.head()| Number | Date Occurred | Time Occurred | Location | Call Type | Description | Disposition | Main Officer | |
|---|---|---|---|---|---|---|---|---|
| 0 | NF-00051317-24 | 11/17/2024 | 708 | 300 3RD ST, NIAGARA FALLS, NEW YORK | STOLEN VEHICLE | VEH WAS PARKED IN CITY LOT. NO LONGER THERE. > | 01 -CRIME REPORT | BAUMANN, JACK |
| 1 | NF-00051302-24 | 11/17/2024 | 208 | 300 3RD ST, NIAGARA FALLS, NEW YORK | PREMISE CHECK | None | 37-CHECKED - ALL OK | ALCIME, ADONIS S |
| 2 | NF-00051298-24 | 11/17/2024 | 153 | 300 3RD ST, NIAGARA FALLS, | PREMISE CHECK | None | 37-CHECKED - ALL OK | CLAPS, BRANDAN |
| 3 | NF-00051026-24 | 11/15/2024 | 141 | 300 3RD ST, NIAGARA FALLS, | PREMISE CHECK | None | 37-CHECKED - ALL OK | GIZZARELLI, RYAN |
| 4 | NF-00051010-24 | 11/14/2024 | 2357 | 300 3RD ST, NIAGARA FALLS, NEW YORK | PREMISE CHECK | Sheraton Hotel | 37-CHECKED - ALL OK | SHIHADAH, BAHA A |
Now we're going to go through each additional page, extracting the table, adding it to a list of pandas dataframes. At the end we'll then combine them all into one big dataframe.
Note that the first page is the only one with column headers. We used a simple .to_df() before, but now we need to say headers=columns to manually set the headers of each dataframe. If we didn't do this pandas wouldn't be able to stack them all together.
dataframes = [first_table]
for page in pages:
guides = Guides(page)
guides.vertical = base.vertical
guides.horizontal.from_content(page.find_all('text:starts-with(NF-)'))
single_df = guides.extract_table().to_df(header=columns)
dataframes.append(single_df)
print("We made", len(dataframes), "dataframes")We made 44 dataframes
Now we can use pd.concat to combine them all.
import pandas as pd
df = pd.concat(dataframes, ignore_index=True)
df.head()| Number | Date Occurred | Time Occurred | Location | Call Type | Description | Disposition | Main Officer | |
|---|---|---|---|---|---|---|---|---|
| 0 | NF-00051317-24 | 11/17/2024 | 708 | 300 3RD ST, NIAGARA FALLS, NEW YORK | STOLEN VEHICLE | VEH WAS PARKED IN CITY LOT. NO LONGER THERE. > | 01 -CRIME REPORT | BAUMANN, JACK |
| 1 | NF-00051302-24 | 11/17/2024 | 208 | 300 3RD ST, NIAGARA FALLS, NEW YORK | PREMISE CHECK | None | 37-CHECKED - ALL OK | ALCIME, ADONIS S |
| 2 | NF-00051298-24 | 11/17/2024 | 153 | 300 3RD ST, NIAGARA FALLS, | PREMISE CHECK | None | 37-CHECKED - ALL OK | CLAPS, BRANDAN |
| 3 | NF-00051026-24 | 11/15/2024 | 141 | 300 3RD ST, NIAGARA FALLS, | PREMISE CHECK | None | 37-CHECKED - ALL OK | GIZZARELLI, RYAN |
| 4 | NF-00051010-24 | 11/14/2024 | 2357 | 300 3RD ST, NIAGARA FALLS, NEW YORK | PREMISE CHECK | Sheraton Hotel | 37-CHECKED - ALL OK | SHIHADAH, BAHA A |
Done!